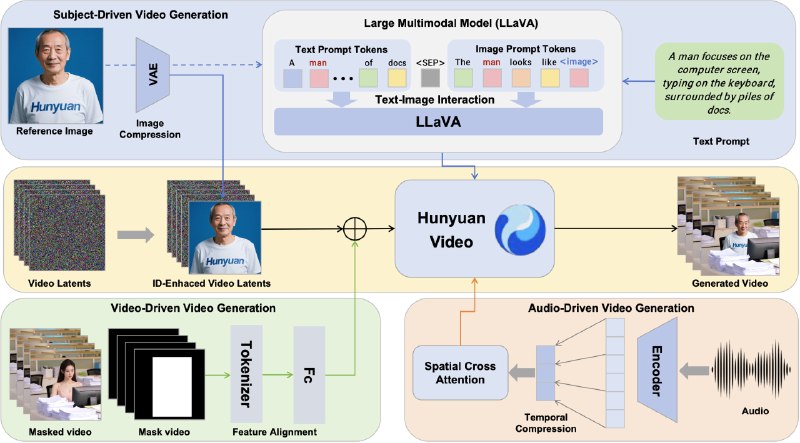
Tencent выпустила HunyuanCustom, фреймворк, который не только генерирует видео по заданным условиям, но и умеет сохранять консистентность субъектов, будь то человек, животное или предмет. Модель справляется даже с мультисубъектными сценами: в демо-роликах люди естественно взаимодействуют с предметами, а текст на упаковках не плывет между кадрами.
В основе модели лежит улучшенный механизм слияния текста и изображений через LLaVA. Например, если вы загружаете фото женщины в платье и текст «танцует под дождем», система анализирует оба инпута, связывая описание с визуальными деталями.
Но главное - это модуль временной конкатенации: он «растягивает» особенности изображения вдоль временной оси видео, используя 3D-VAE. Это помогает избежать «прыгающих» лиц или внезапных изменений фона, проблемы, которая характерна даже для топовых моделей видеогенерации.
Tencent переработали и пайплайн аудио. Для синхронизации звука с движениями губ или действиями в кадре HunyuanCustom использует AudioNet, модуль, который выравнивает аудио- и видеофичи через пространственное кросс-внимание.
Фреймворк поддерживает возможность замены объекта в готовом ролике (скажем, подставить новую модель кроссовок в рекламу), модель сжимает исходное видео в латентное пространство, выравнивает его с шумными данными и встраивает изменения без артефактов на границах.
Экспериментальные тесты показали, что HunyuanCustom обходит конкурентов по ключевым метрикам. Например, Face-Sim (сохранение идентичности лица) у Tencent — 0.627 против 0.526 у Hailuo, а с Keling, Vidu, Pika и Skyreels разрыв еще больше.
⚠️ Для работы модель требует минимум 24 ГБ видеопамяти для роликов 720p, но чтобы раскрыть все возможности, разработчики рекомендуют 80 ГБ VRAM.
Код и чекпоинты уже доступны в открытом доступе, а в репозитории есть примеры запуска как на нескольких GPU, так и в экономном режиме для потребительских видеокарт.
@ai_machinelearning_big_data
#AI #ML #Video #HunyuanCustom #Tencent
Create: Update:

>>Click here to continue<<
Data Science by ODS.ai 🦜

Share with your best friend
VIEW MORE