WavChat: A Survey of Spoken Dialogue Models. Часть 1/4
Сегодня поделимся суммаризацией главным из большого обзора разговорных ИИ. Сначала он кажется неплохой попыткой систематизировать происходящее в мире ALM: авторы анализируют тренды и на основе существующих публикаций пытаются понять, куда всë идёт и как было бы лучше. Но в какой-то момент статья начинает повторять саму себя. Тем не менее, лучшей попытки осознать происходящее мы не нашли. Давайте разбираться.
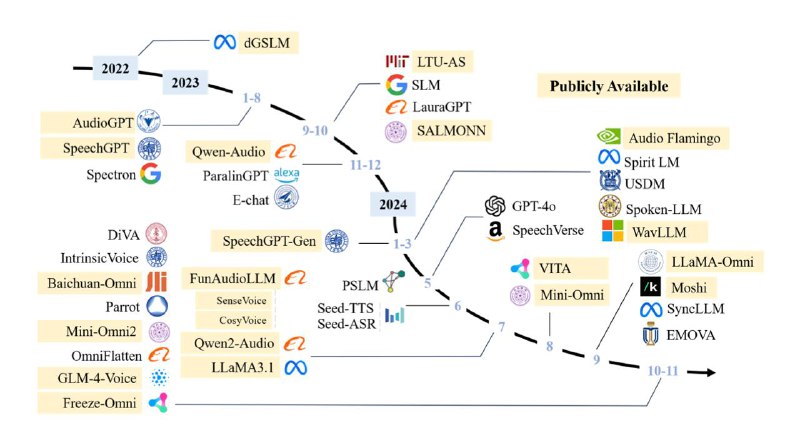
Идея объединить аудиомодальность с LLM давно будоражит умы академии и индустрии. Но долгое время никто толком не мог понять, для чего это нужно. Первой значимой попыткой можно назвать Whisper, который заставил seq2seq-модель предсказывать не только ASR, но и перевод.
На диаграмме легко заметить, какой именно момент развития ALM стал переломным и сделал очевидным, что нужно двигаться к разговорным моделям: когда коммьюнити узнало о GPT-4o. OpenAI показали, как аудиомодальность может сделать диалог с LLM естественным, почти бесшовным, решая между делом не только задачи распознавания синтеза, но и, например, классификацию скорости дыхания.
Авторы считают, что всё нужно свести к voice-to-voice диалоговому стеку. Его можно собрать из последовательной работы моделей (ASR-LLM-TTS), сделать end2end или составить из частичных фьюзов отдельных компонент. Трёхстадийный каскад ASR-LLM-TTS при этом предлагается считать бейслайном, о который нужно калиброваться. И побеждать его — учиться понимать особенности речи, воспринимать звуки, уместно отвечать или, наоборот, пропускать реплики.
В статье выделяют девять навыков, которыми должны обладать диалоговые модели:
- Text Intelligence;
- Speech Intelligence;
- Audio and Music Generation;
- Audio and Music Understanding;
- Multilingual Capability;
- Context Learning;
- Interaction Capability;
- Streaming Latency;
- Multimodal Capability.
Всё, что опубликовано по теме диалоговых систем за последний год, авторы предлагают классифицировать по разным признакам:
- Архитектура: end2end- и каскадные модели.
- Способ представления звука: токенизация или энкодер.
- Парадигма тренировки: использовали ли пост-претрейн, какие задачи решали.
- Подход к обеспечению диалоговости: стриминг, симплекс, дюплекс, полудюплекс.
Дальше попробуем пошагово проследить эту классификацию.
Продолжение следует.
Никита Рыжиков
Create: Update:

>>Click here to continue<<
Data Science by ODS.ai 🦜
Share with your best friend
VIEW MORE