Channel: Новое электричество

AlphaFold
Прогнозирование сворачивания белков (protein folding) - сложная задача, решение которой может помочь лучше понимать и лечить болезни. Последние 50 лет решение почти никак не продвигалось, но одна, возникшая из ниоткуда, команда исследователей возможно решила проблему.
Белки состоят из аминокислот. Получить аминокислотную последовательность белка в наши дни довольно просто. Но перейти от этой последовательности к трехмерной форме белка крайне сложно.
На протяжении десятилетий исследователи разрабатывали белковые структуры, используя медленные и дорогостоящие методы, такие как рентгеновская кристаллография. Пока что с помощью этих подходов мы решили только около 170 тысяч белков. При этом, всего более 200 миллионов белков были обнаружены в земных формах жизни.
Возможность предсказать форму белка на основе его аминокислотной последовательности навсегда изменит правила игры. Человечество могло бы быстрее разрабатывать лекарства, но компьютерные методики прогнозирования до сих пор были недостаточно точными, чтобы на них можно было полагаться.
Команда DeepMind создала “конвейер глубокого обучения“ (deep learning pipeline) для прогнозирования формы белка по его аминокислотной последовательности и участвовали с ним в конкурсе «Критическая оценка прогнозирования структуры белка» (CASP). В конкурсе командам дают последовательности аминокислот для ~100 белков с неизвестной структурой и просят предсказать форму. Предсказаниям присваивается оценка от 0 до 100. Медленные методы (например, рентгеновская кристаллография) обычно оцениваются не выше 90.
Первая версия модели (AlphaFold) работает следующим образом:
- во-первых, она ищет фрагменты последовательности, похожие на интересующий белок, в большой базе данных последовательностей белков. Это помогает определить искомые особенности белка. Автоэнкодер предсказывает, какую форму белка наиболее вероятно представляет фрагмент последовательности;
- затем эти особенности передаются в конволютную нейронную сеть, которая предсказывает расстояния между различными частями белковой последовательности. Прогнозирование расстояний позволяет также прогнозировать точки контакта;
- далее, используя предсказанные расстояния и точки контакта, модель рассматривает все возможные формы белка и определяет наиболее вероятную.
В обновленной модели (AlphaFold-2) были внесены изменения. Команда еще не опубликовала полноценную научную статью (пока только реферат), но, насколько можно судить, исследователи использовали глубокое обучение на основе внимания (attention-based), чтобы учитывать всю форму белка разом, а не фрагментальную последовательность.
С начала конкурса в 1994 и до 2016 года баллы CASP в среднем были около 40. Первый DeepMind набрал около 60. В этом году AlphaFold набрал в среднем 92,4 балла, преодолев порог в 90 баллов!
Забавно то что, организаторы конкурса подумали, что DeepMind жульничает и поставили перед ним особую задачу - мембранный белок из древних видов архей. В течение последних 10 лет группы исследователей безуспешно перепробовали все возможные уловки, чтобы получить кристаллическую структуру белка методом рентгеновской кристаллографии. AlphaFold не испытывая проблем генерировал изображение трехчастного белка с двумя спиральными ветвями. Оглядываясь назад, легко увидеть, что эта структура идеально соответствовала данным рентгеновской кристаллографии.
Кажется, что острая проблема, над которой исследователи и фармацевтические компании работают более 50 лет на грани решения. Это может значительно ускорить разработку широкого спектра лекарств: от противораковых, которые лучше воздействуют на белки для репликации клеток, до антибиотиков, нацеленных на поверхностные рецепторы микробов. Более того, обучение этой модели значительно дешевле любой современной технологии - всего несколько недель на небольшом кластере серверов.
Очень возможно, что в течение следующих 10 лет мы с вами увидим не только высадку на Марс, но и лекарства от многих видов рака.
Прогнозирование сворачивания белков (protein folding) - сложная задача, решение которой может помочь лучше понимать и лечить болезни. Последние 50 лет решение почти никак не продвигалось, но одна, возникшая из ниоткуда, команда исследователей возможно решила проблему.
Белки состоят из аминокислот. Получить аминокислотную последовательность белка в наши дни довольно просто. Но перейти от этой последовательности к трехмерной форме белка крайне сложно.
На протяжении десятилетий исследователи разрабатывали белковые структуры, используя медленные и дорогостоящие методы, такие как рентгеновская кристаллография. Пока что с помощью этих подходов мы решили только около 170 тысяч белков. При этом, всего более 200 миллионов белков были обнаружены в земных формах жизни.
Возможность предсказать форму белка на основе его аминокислотной последовательности навсегда изменит правила игры. Человечество могло бы быстрее разрабатывать лекарства, но компьютерные методики прогнозирования до сих пор были недостаточно точными, чтобы на них можно было полагаться.
Команда DeepMind создала “конвейер глубокого обучения“ (deep learning pipeline) для прогнозирования формы белка по его аминокислотной последовательности и участвовали с ним в конкурсе «Критическая оценка прогнозирования структуры белка» (CASP). В конкурсе командам дают последовательности аминокислот для ~100 белков с неизвестной структурой и просят предсказать форму. Предсказаниям присваивается оценка от 0 до 100. Медленные методы (например, рентгеновская кристаллография) обычно оцениваются не выше 90.
Первая версия модели (AlphaFold) работает следующим образом:
- во-первых, она ищет фрагменты последовательности, похожие на интересующий белок, в большой базе данных последовательностей белков. Это помогает определить искомые особенности белка. Автоэнкодер предсказывает, какую форму белка наиболее вероятно представляет фрагмент последовательности;
- затем эти особенности передаются в конволютную нейронную сеть, которая предсказывает расстояния между различными частями белковой последовательности. Прогнозирование расстояний позволяет также прогнозировать точки контакта;
- далее, используя предсказанные расстояния и точки контакта, модель рассматривает все возможные формы белка и определяет наиболее вероятную.
В обновленной модели (AlphaFold-2) были внесены изменения. Команда еще не опубликовала полноценную научную статью (пока только реферат), но, насколько можно судить, исследователи использовали глубокое обучение на основе внимания (attention-based), чтобы учитывать всю форму белка разом, а не фрагментальную последовательность.
С начала конкурса в 1994 и до 2016 года баллы CASP в среднем были около 40. Первый DeepMind набрал около 60. В этом году AlphaFold набрал в среднем 92,4 балла, преодолев порог в 90 баллов!
Забавно то что, организаторы конкурса подумали, что DeepMind жульничает и поставили перед ним особую задачу - мембранный белок из древних видов архей. В течение последних 10 лет группы исследователей безуспешно перепробовали все возможные уловки, чтобы получить кристаллическую структуру белка методом рентгеновской кристаллографии. AlphaFold не испытывая проблем генерировал изображение трехчастного белка с двумя спиральными ветвями. Оглядываясь назад, легко увидеть, что эта структура идеально соответствовала данным рентгеновской кристаллографии.
Кажется, что острая проблема, над которой исследователи и фармацевтические компании работают более 50 лет на грани решения. Это может значительно ускорить разработку широкого спектра лекарств: от противораковых, которые лучше воздействуют на белки для репликации клеток, до антибиотиков, нацеленных на поверхностные рецепторы микробов. Более того, обучение этой модели значительно дешевле любой современной технологии - всего несколько недель на небольшом кластере серверов.
Очень возможно, что в течение следующих 10 лет мы с вами увидим не только высадку на Марс, но и лекарства от многих видов рака.
Google DeepMind
Artificial intelligence could be one of humanity’s most useful inventions. We research and build safe artificial intelligence systems. We're committed to solving intelligence, to advance science...
Время от времени к нам обращаются друзья с просьбой порекомендовать хороших людей ИТ-специальностей. По опыту знаем, что найти таких людей совсем непросто, а также знаем, что их немало среди подписчиков нашего канала. Мы решили попробовать размещать в канал вакансии – только в случаях когда уверены, что она реальная и все обязательства будут выполнены.
Сегодня размещаем вакансию фронтенд-разработчика (частичная занятость) на проект в крупную западную компанию. У кого есть интерес, задавайте вопросы @new_electricity_bot, а еще лучше скидывайте резюме!
Сегодня размещаем вакансию фронтенд-разработчика (частичная занятость) на проект в крупную западную компанию. У кого есть интерес, задавайте вопросы @new_electricity_bot, а еще лучше скидывайте резюме!
Telegraph
Фронтенд-разрабочик на проект
Требования Удаленный фрилансер со следующими навыками: - Уверенное владение HTML5, CCS3 и понимание принципов семантической верстки; - Уверенное владение одним из популярных фреймворков: React, Vue, Angular - Опыт резиновой и адаптивной верстки; - Уверенное…
#ai_politics
Развитие AI неизбежно влечет за собой массу рисков – как технологических, так и политических. Взять ту же технологию распознавания лиц – уже сейчас она развита настолько, что позволяет ряду авторитарных режимов серьезно повышать эффективность слежения за гражданами (гуглите кейс Китая с уйгурами).
В сегодняшнем посте разберемся, какие меры принимают государства по всему миру для того, чтобы сделать технологию face recognition безопаснее. В конце концов, от их решений во многом зависит то, на какую кривую развития AI мы выйдем в ближайшие годы:
Развитие AI неизбежно влечет за собой массу рисков – как технологических, так и политических. Взять ту же технологию распознавания лиц – уже сейчас она развита настолько, что позволяет ряду авторитарных режимов серьезно повышать эффективность слежения за гражданами (гуглите кейс Китая с уйгурами).
В сегодняшнем посте разберемся, какие меры принимают государства по всему миру для того, чтобы сделать технологию face recognition безопаснее. В конце концов, от их решений во многом зависит то, на какую кривую развития AI мы выйдем в ближайшие годы:
Telegraph
Узнай меня, если сможешь
По статистике, в 50% стран в мире сейчас так или иначе присутствует технология распознавания лиц. Всего 3 страны (Бельгия, Люксембург и Марокко) законодательно ввели запреты на использование технологии в некоторых целях.
Всем привет!
Год подходит к концу — сегодня вспомним, чем AI удивлял и радовал нас в этом году.
Одним из главных событий стал релиз движка GPT-3, самого большого по количеству параметров в мире. Здесь мы обсуждали, стоит ли считать GPT-3 серьёзным шагом к появлению общего ИИ, а также пару раз писали о его применениях: способностях вести блог и генерить мемасики.
ИИ всё активно проникает во все сферы жизни. Так, Американская Комиссия по торговле товарными фьючерсами ("CFTC") с помощью AI смогла доказать факт манипуляций ценами серебра крупными банками, во главе с JP Morgan — что же будет, когда ЦБ освоит такие технологии... А буквально недавно AlphaFold научился предсказывать сворачивание белков.
Используя нейронные сети, можно заметно улучшить качество старых видео. Вот, например, очень любопытное видео Нью-Йорка начала 20 века.
Наконец, вышло новое поколение видеокарт NVIDIA — RTX 30, и сделало домашние ИИ-вычисления ещё доступнее. Совсем необязательно покупать Titan RTX за 2500 долларов, вполне можно обойтись картой в 3-4 раза дешевле. Недавно мы обсуждали, почему вычисления на GPU быстрее, чем на CPU, рассказывали про скорость RTX 30.
Конечно, событий было намного больше. Пишите в комментариях, чем вам запомнился ИИ в 2020 году!
Год подходит к концу — сегодня вспомним, чем AI удивлял и радовал нас в этом году.
Одним из главных событий стал релиз движка GPT-3, самого большого по количеству параметров в мире. Здесь мы обсуждали, стоит ли считать GPT-3 серьёзным шагом к появлению общего ИИ, а также пару раз писали о его применениях: способностях вести блог и генерить мемасики.
ИИ всё активно проникает во все сферы жизни. Так, Американская Комиссия по торговле товарными фьючерсами ("CFTC") с помощью AI смогла доказать факт манипуляций ценами серебра крупными банками, во главе с JP Morgan — что же будет, когда ЦБ освоит такие технологии... А буквально недавно AlphaFold научился предсказывать сворачивание белков.
Используя нейронные сети, можно заметно улучшить качество старых видео. Вот, например, очень любопытное видео Нью-Йорка начала 20 века.
Наконец, вышло новое поколение видеокарт NVIDIA — RTX 30, и сделало домашние ИИ-вычисления ещё доступнее. Совсем необязательно покупать Titan RTX за 2500 долларов, вполне можно обойтись картой в 3-4 раза дешевле. Недавно мы обсуждали, почему вычисления на GPU быстрее, чем на CPU, рассказывали про скорость RTX 30.
Конечно, событий было намного больше. Пишите в комментариях, чем вам запомнился ИИ в 2020 году!
Telegram
Новое электричество
От AI не спрячешься
#ai_trends
Искусственный интеллект открывает властям невиданные доселе возможности. Негативная сторона - честные граждане теряют возможность жить в тени государственных софитов. Но с точки зрения борьбы с преступностью выгоды велики.…
#ai_trends
Искусственный интеллект открывает властям невиданные доселе возможности. Негативная сторона - честные граждане теряют возможность жить в тени государственных софитов. Но с точки зрения борьбы с преступностью выгоды велики.…
Что в черном ящике?
Искусственный интеллект, стоящий за беспилотными автомобилями, анализом медицинских изображений и другими приложениями компьютерного зрения, основан на глубоких нейронных сетях.
Как мы уже неоднократно писали, глубокие сети, сложно смоделированные на основе мозга, состоят из слоев взаимосвязанных нейронов - математических функций, которые отправляют и получают информацию, срабатывая в ответ на входной сигнал. Первый уровень обрабатывает сырые данные, такие как пиксели в изображении, и передает эту информацию на следующий уровень выше, “запуская” некоторые из нейронов, которые затем передают сигнал более высоким уровням, пока в конечном итоге сеть не придет к определению того, что находится во входном изображении.
Но вот в чем проблема, - говорит Синтия Рудин, профессор компьютерных наук института Дьюк. «Мы можем ввести, скажем, медицинское изображение и наблюдать, что выходит на другом конце, например, «это картина злокачественного поражения», но трудно понять, что произошло между входом и выходом».
Это так называемая проблема «черного ящика». То, что происходит в “сознании” машины - в скрытых слоях нейронной сети - часто непостижимо даже для людей, которые ее построили.
продолжение
Искусственный интеллект, стоящий за беспилотными автомобилями, анализом медицинских изображений и другими приложениями компьютерного зрения, основан на глубоких нейронных сетях.
Как мы уже неоднократно писали, глубокие сети, сложно смоделированные на основе мозга, состоят из слоев взаимосвязанных нейронов - математических функций, которые отправляют и получают информацию, срабатывая в ответ на входной сигнал. Первый уровень обрабатывает сырые данные, такие как пиксели в изображении, и передает эту информацию на следующий уровень выше, “запуская” некоторые из нейронов, которые затем передают сигнал более высоким уровням, пока в конечном итоге сеть не придет к определению того, что находится во входном изображении.
Но вот в чем проблема, - говорит Синтия Рудин, профессор компьютерных наук института Дьюк. «Мы можем ввести, скажем, медицинское изображение и наблюдать, что выходит на другом конце, например, «это картина злокачественного поражения», но трудно понять, что произошло между входом и выходом».
Это так называемая проблема «черного ящика». То, что происходит в “сознании” машины - в скрытых слоях нейронной сети - часто непостижимо даже для людей, которые ее построили.
продолжение
Telegraph
Что в черном ящике?
«Проблема с моделями глубокого обучения в том, что они настолько сложны, что мы фактически не знаем, чему они обучились», - говорит Жи Чен, студент в лаборатории Рудина в Дьюке. «Они могут учитывать информацию, которую мы не хотели бы и как следствие их “рассуждения”…
#ai_startups
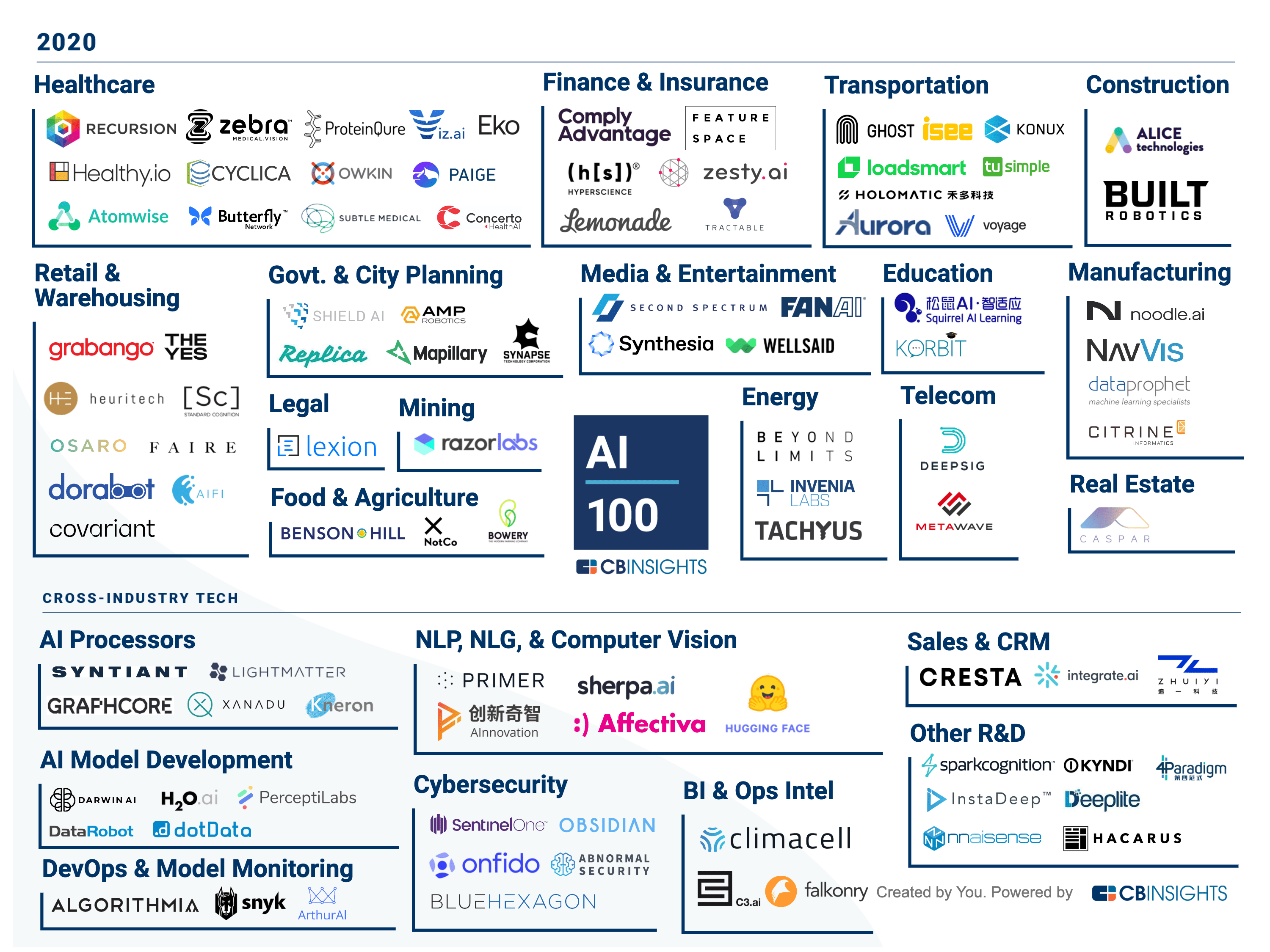
Всем привет! Пока вы доедаете остатки оливье и собираетесь с мыслями, Новое Электричество подготовило для вас топ-100 AI-стартапов 2020.
Список был составлен известной платформой CB Insights и будем полезен как тем, кто хочет инвестировать в перспективные технологические компании, так и тем, кто просто следит за трендами в сфере AI.
При составлении списка CB Insights использовал довольно сложную методологию, учитывая следующие факторы:
- Анализ патентов, чтобы определить силу R&D компании
- Финансовое состояние
- Трендовость
- Отношения с бизнес-партнерами
- Конкурентный анализ
- Рыночные новости
Далее пройдемся по основным выводам из отчета.
В 2020 г. Стартапы из топ-100 привлекли $7,4 млрд от 600+ инвесторов в более, чем 300 сделках.
В список также вошли 10 «единорогов», предлагающих комплексные AI-решения. Так, Faire использует машинное обучение, чтобы мэтчить местных ритейлеров с товарами, которые имеют шанс хорошо продаваться в этой географической зоне.
Butterfly Network производит карманный прибор для диагностики ультразвуком, а DataRobot предлагает решения, помогающие клиентам создавать AI-приложения.
В списке также присутствуют стартапы на совсем ранней стадии развития – например, Caspar AI, производящий решения для умных домов (ребята недавно заключили контракты с Panasonic и The Wolff). Стоит отдельно отметить еще одного выдающегося новичка: Razor Labs, предоставляющие AI-решения добывающим компаниям.
В 2020 г. Компании из топ-100 разделились на 15 основных отраслей, самыми доминирующими из которых стали Healthcare, Retail и Finance&Insurance.
Наиболее заметными компаниям из сферы здравоохранения стали Eko (производство AI-софта для стетоскопов), Healthy IO (превращает смартфоны в лаборатории по диагностике с помощью анализа мочи) и Subtle Medical (использует AI для улучшения качества изображений после радиографии).
В разрезе стран ожидаемо доминирует США (65% от общего числа компаний), но также есть неожиданные новички, такие, как Чили, Швеция и Южная Африка. Всего компании ТОП-100 представляют 13 стран (стоит отдельно отметить 8 стартапов из Канады, 8 из Великобритании и всего 6 из Китая).
Сама карта приложена к посту. Желаем всем продуктивного начала года, оставайтесь с нами, впереди еще много интересных постов!
Всем привет! Пока вы доедаете остатки оливье и собираетесь с мыслями, Новое Электричество подготовило для вас топ-100 AI-стартапов 2020.
Список был составлен известной платформой CB Insights и будем полезен как тем, кто хочет инвестировать в перспективные технологические компании, так и тем, кто просто следит за трендами в сфере AI.
При составлении списка CB Insights использовал довольно сложную методологию, учитывая следующие факторы:
- Анализ патентов, чтобы определить силу R&D компании
- Финансовое состояние
- Трендовость
- Отношения с бизнес-партнерами
- Конкурентный анализ
- Рыночные новости
Далее пройдемся по основным выводам из отчета.
В 2020 г. Стартапы из топ-100 привлекли $7,4 млрд от 600+ инвесторов в более, чем 300 сделках.
В список также вошли 10 «единорогов», предлагающих комплексные AI-решения. Так, Faire использует машинное обучение, чтобы мэтчить местных ритейлеров с товарами, которые имеют шанс хорошо продаваться в этой географической зоне.
Butterfly Network производит карманный прибор для диагностики ультразвуком, а DataRobot предлагает решения, помогающие клиентам создавать AI-приложения.
В списке также присутствуют стартапы на совсем ранней стадии развития – например, Caspar AI, производящий решения для умных домов (ребята недавно заключили контракты с Panasonic и The Wolff). Стоит отдельно отметить еще одного выдающегося новичка: Razor Labs, предоставляющие AI-решения добывающим компаниям.
В 2020 г. Компании из топ-100 разделились на 15 основных отраслей, самыми доминирующими из которых стали Healthcare, Retail и Finance&Insurance.
Наиболее заметными компаниям из сферы здравоохранения стали Eko (производство AI-софта для стетоскопов), Healthy IO (превращает смартфоны в лаборатории по диагностике с помощью анализа мочи) и Subtle Medical (использует AI для улучшения качества изображений после радиографии).
В разрезе стран ожидаемо доминирует США (65% от общего числа компаний), но также есть неожиданные новички, такие, как Чили, Швеция и Южная Африка. Всего компании ТОП-100 представляют 13 стран (стоит отдельно отметить 8 стартапов из Канады, 8 из Великобритании и всего 6 из Китая).
Сама карта приложена к посту. Желаем всем продуктивного начала года, оставайтесь с нами, впереди еще много интересных постов!
{kind=link}
Назад к движению
Профессор Гордон Ченг из Технического Университета Мюнхена, тренируя пациентов с параличом нижних конечностей ходить в моторизированном экзоскелете в рамках сенсационного исследовательского проекта «Иди снова» ("Walk Again") в 2016-м году, обнаружил, что пациенты восстановили определенную степень контроля над движениями своих ног.
"Хотя четыре года назад у нас был прорыв, это было только начало. К моему сожалению, ни один из этих пациентов пока не ходит свободно и без посторонней помощи. Мы коснулись только верхушки айсберга. Чтобы разработать более совершенные медицинские устройства, нам нужно глубже понять, как работает мозг, и как воплотить это в робототехнике", — говорит Ченг.
Идея заключается в том, что связь между мозгом и машиной должна работать так, чтобы мозг воспринимал машину как продолжение тела. Возьмем, к примеру, вождение. За рулем машины ты не думаешь о своих движениях. Но мы до сих пор не знаем, как это работает на самом деле. Теория заключается в том, что мозг каким-то образом адаптируется к машине, как если бы она была частью тела. Имея в виду эту общую идею, рождается мысль иметь экзоскелет, который таким же образом воспринимался бы мозгом.
Экзоскелет, который использовала команда Ченга для исследований по его словам до сих пор представляет собой просто большой кусок металла и, следовательно, довольно громоздок для пользователя. "Я хочу разработать «мягкий» экзоскелет — что-то, что вы можете просто носить как предмет одежды, который может одновременно определять намерения пользователя и обеспечивать мгновенную обратную связь", — поясняет Ченг. Интеграция такого устройства с последними достижениями в области интерфейсов мозг-машина, которые позволяют измерять реакции мозга в реальном времени (например, Neuralink), позволяет адаптировать такие экзоскелеты к потребностям каждого пользователя, особенно учитывая последние технологические достижения и лучшее понимание того, как декодировать считанную активность мозга пользователя.
Что еще не хватает?
Например роботов, которые ближе и к человеческому поведению и к конструкции человеческого тела. Например, робот-гуманоид с искусственными мышцами. Эта естественная (природная) конструкция, имитирующая мышцы, вместо традиционного моторизованного приведения в действие, предоставит нейробиологам более реалистичную модель для своих исследований и будет способствовать более глубокому сотрудничеству между нейробиологией и робототехникой в будущем.
Объединение двух дисциплин робототехники и нейробиологии — сложное упражнение, это одна из основных причин, по которой Ченг создал элитную программу магистратуры в области нейроинженерии, первую и единственную в своем роде в Германии. "Для меня важно научить студентов мыслить шире и в разных дисциплинах, чтобы находить ранее невообразимые решения. Вот почему преподаватели из разных областей, например, из больниц или со спортивного факультета, обучают наших студентов. Нам нужно создать новое сообщество и новую культуру в области инженерии. С моей точки зрения, образование — ключевой фактор."
Профессор Гордон Ченг из Технического Университета Мюнхена, тренируя пациентов с параличом нижних конечностей ходить в моторизированном экзоскелете в рамках сенсационного исследовательского проекта «Иди снова» ("Walk Again") в 2016-м году, обнаружил, что пациенты восстановили определенную степень контроля над движениями своих ног.
"Хотя четыре года назад у нас был прорыв, это было только начало. К моему сожалению, ни один из этих пациентов пока не ходит свободно и без посторонней помощи. Мы коснулись только верхушки айсберга. Чтобы разработать более совершенные медицинские устройства, нам нужно глубже понять, как работает мозг, и как воплотить это в робототехнике", — говорит Ченг.
Идея заключается в том, что связь между мозгом и машиной должна работать так, чтобы мозг воспринимал машину как продолжение тела. Возьмем, к примеру, вождение. За рулем машины ты не думаешь о своих движениях. Но мы до сих пор не знаем, как это работает на самом деле. Теория заключается в том, что мозг каким-то образом адаптируется к машине, как если бы она была частью тела. Имея в виду эту общую идею, рождается мысль иметь экзоскелет, который таким же образом воспринимался бы мозгом.
Экзоскелет, который использовала команда Ченга для исследований по его словам до сих пор представляет собой просто большой кусок металла и, следовательно, довольно громоздок для пользователя. "Я хочу разработать «мягкий» экзоскелет — что-то, что вы можете просто носить как предмет одежды, который может одновременно определять намерения пользователя и обеспечивать мгновенную обратную связь", — поясняет Ченг. Интеграция такого устройства с последними достижениями в области интерфейсов мозг-машина, которые позволяют измерять реакции мозга в реальном времени (например, Neuralink), позволяет адаптировать такие экзоскелеты к потребностям каждого пользователя, особенно учитывая последние технологические достижения и лучшее понимание того, как декодировать считанную активность мозга пользователя.
Что еще не хватает?
Например роботов, которые ближе и к человеческому поведению и к конструкции человеческого тела. Например, робот-гуманоид с искусственными мышцами. Эта естественная (природная) конструкция, имитирующая мышцы, вместо традиционного моторизованного приведения в действие, предоставит нейробиологам более реалистичную модель для своих исследований и будет способствовать более глубокому сотрудничеству между нейробиологией и робототехникой в будущем.
Объединение двух дисциплин робототехники и нейробиологии — сложное упражнение, это одна из основных причин, по которой Ченг создал элитную программу магистратуры в области нейроинженерии, первую и единственную в своем роде в Германии. "Для меня важно научить студентов мыслить шире и в разных дисциплинах, чтобы находить ранее невообразимые решения. Вот почему преподаватели из разных областей, например, из больниц или со спортивного факультета, обучают наших студентов. Нам нужно создать новое сообщество и новую культуру в области инженерии. С моей точки зрения, образование — ключевой фактор."
Wikipedia
Neuralink
American brain-computer interface company
Всем привет!
Сегодня, после недавней инаугурации Байдена, хотелось бы поговорить о том, насколько мощным фактором избирательной кампании США становится AI.
Прошли времена политических гаданий о предпочтениях избирателей и массового распространения брошюр о позициях кандидатов на высшие должности в стране. Используя увеличивающееся количество и разнообразие информации об избирателях, политики, правительства и социальные группы имеют в своем распоряжении больше инструментов, чем когда-либо, для продвижения повестки дня и кандидатов.
Кампания Обамы стояла на переднем крае внедрения передовой аналитики данных и целевой рекламы в политическую сферу с помощью машинного обучения, создавая «сложные аналитические модели, которые персонализировали социальные сети и обмен сообщениями по электронной почте с использованием данных, генерируемых активностью в социальных сетях».
Это стремление к анализу данных способствовало успеху демократов в 2008 году, а в 2012 году планку подняли еще сильнее, создав команду из более чем сотни аналитиков биг дата, которые успешно создали множество инструментов для прогнозного моделирования и руководства принятием стратегических решений.
Нет сомнений в том, что AI и машинное обучение в политике продвинулись вперед со времен 2008 года. Теперь эти инструменты, в том числе, используются для анализа рекламных шаблонов, выявления вероятности принятия закона, запуска ботов, которые борются с фейковыми новостями и дезинформацией, а также для информирования избирателей о различных кандидатах и их программах.
Руководствуясь первым успешным применением президентом Обамой биг дата в своих кампаниях 2008 и 2012 годов, политтехнологи вывели кампании 2016 и 2020 годов на новый уровень. В ходе расследования по кампании Хиллари Клинтон в 2016 году, газета Washington Post показала, что кампания почти полностью проводилась с помощью алгоритма машинного обучения под названием «Ада».
В частности, алгоритм играл роль практически в каждом стратегическом решении, которое принимали помощники Клинтон, включая то, где и когда провести ралли, где транслировать телевизионную рекламу, а также когда не стоило выходить на публику.
Анализируя роль технологий в политическом дискурсе на выборах 2020 года, The Atlantic обнаружили, что примерно пятая часть всех твитов о президентских выборах 2016 года была опубликована ботами, как и примерно треть всех твитов о голосовании за Brexit в этом году.
Эта гонка только начинается и стоит ожидать все большего внедрения AI в политические процессы других стран, что, в идеале, должно привести к созданию стандартных правил и этических кодексов в отношении AI и машинного обучения.
Сегодня, после недавней инаугурации Байдена, хотелось бы поговорить о том, насколько мощным фактором избирательной кампании США становится AI.
Прошли времена политических гаданий о предпочтениях избирателей и массового распространения брошюр о позициях кандидатов на высшие должности в стране. Используя увеличивающееся количество и разнообразие информации об избирателях, политики, правительства и социальные группы имеют в своем распоряжении больше инструментов, чем когда-либо, для продвижения повестки дня и кандидатов.
Кампания Обамы стояла на переднем крае внедрения передовой аналитики данных и целевой рекламы в политическую сферу с помощью машинного обучения, создавая «сложные аналитические модели, которые персонализировали социальные сети и обмен сообщениями по электронной почте с использованием данных, генерируемых активностью в социальных сетях».
Это стремление к анализу данных способствовало успеху демократов в 2008 году, а в 2012 году планку подняли еще сильнее, создав команду из более чем сотни аналитиков биг дата, которые успешно создали множество инструментов для прогнозного моделирования и руководства принятием стратегических решений.
Нет сомнений в том, что AI и машинное обучение в политике продвинулись вперед со времен 2008 года. Теперь эти инструменты, в том числе, используются для анализа рекламных шаблонов, выявления вероятности принятия закона, запуска ботов, которые борются с фейковыми новостями и дезинформацией, а также для информирования избирателей о различных кандидатах и их программах.
Руководствуясь первым успешным применением президентом Обамой биг дата в своих кампаниях 2008 и 2012 годов, политтехнологи вывели кампании 2016 и 2020 годов на новый уровень. В ходе расследования по кампании Хиллари Клинтон в 2016 году, газета Washington Post показала, что кампания почти полностью проводилась с помощью алгоритма машинного обучения под названием «Ада».
В частности, алгоритм играл роль практически в каждом стратегическом решении, которое принимали помощники Клинтон, включая то, где и когда провести ралли, где транслировать телевизионную рекламу, а также когда не стоило выходить на публику.
Анализируя роль технологий в политическом дискурсе на выборах 2020 года, The Atlantic обнаружили, что примерно пятая часть всех твитов о президентских выборах 2016 года была опубликована ботами, как и примерно треть всех твитов о голосовании за Brexit в этом году.
Эта гонка только начинается и стоит ожидать все большего внедрения AI в политические процессы других стран, что, в идеале, должно привести к созданию стандартных правил и этических кодексов в отношении AI и машинного обучения.
Люди издревле пытались разработать теории, позволяющие надежно определять личностные качества человека по его заметным признакам: лицу, размеру и форме черепа или даже свойствам отдельных частей тела - так появились псевдонауки вроде физиогномики и френологии. Однако настоящая наука расставила все по полкам: на больших выборках никакой прямой связи между физиологическими параметрами человека и его личностными качествами нет.
Возникающие иногда корреляции точнее объясняются опосредованно — социологией и психологией. Иными словами, человек с врожденной травмой лица, скорее всего, будет более остальных озлоблен, несчастен и раздражителен не из-за того, что его голову изувечило до появления на свет. Просто по отношению к таким людям общество более предвзято и несправедливо, поэтому ему приходится реагировать в ответ.
Однако стереотипы сильны, и даже в XXI веке заставляют многих утверждать, будто глубинные свойства личности человека можно надежно считать с внешности. Американский исследователь из Стэнфордского университета Майкл Косински решил использовать самые современные методы, чтобы в очередной раз опровергнуть вышеописанные заблуждения. Вышло наоборот :)
Майкл разработал искусственный интеллект, который узнает ненамного менее интимную характеристику человека по его лицу — политические убеждения. Результаты последнего эксперимента были опубликованы 11 января этого года в рецензируемом журнале Nature Scientific Reports.
Алгоритм проверили более чем на миллионе фотографий реальных людей из США, Канады и Великобритании. Изображения брали из социальных сетей и с сайтов знакомств, а политические убеждения оценивали по бинарной системе «либерал — консерватор». Точность алгоритма оказалась в диапазоне 66-72%. Нейросеть анализировала только овал лица, все остальные детали с изображения отсеивались. Таким образом устранялось влияние посторонних предметов в кадре и окружающей обстановки.
На первый взгляд может показаться, что результаты алгоритма не особо впечатляющие. Но человек в аналогичной ситуации справляется существенно хуже: всего на 55%, что незначительно эффективнее подбрасывания монеты.
Косински предпринял несколько попыток определить хотя бы некоторые из параметров, на которые опирался AI. Он безрезультатно проверил множество признаков: цвет волос на лице, прямой взгляд в камеру у человека или он прячет глаза, различные эмоции. Простые, понятные и привычные людям критерии не сработали: судя по всему, нейросеть нашла что-то еще.
Основной гипотезой сейчас является тот факт, что социальные факторы, отражающиеся в нашей культуре, накладывают отпечаток на внешность. С этим "черным ящиком" нейросети еще предстоит разбираться, но уже сейчас видно, как эта новая модель может использоваться при подготовке к выборам в США и не только.
Возникающие иногда корреляции точнее объясняются опосредованно — социологией и психологией. Иными словами, человек с врожденной травмой лица, скорее всего, будет более остальных озлоблен, несчастен и раздражителен не из-за того, что его голову изувечило до появления на свет. Просто по отношению к таким людям общество более предвзято и несправедливо, поэтому ему приходится реагировать в ответ.
Однако стереотипы сильны, и даже в XXI веке заставляют многих утверждать, будто глубинные свойства личности человека можно надежно считать с внешности. Американский исследователь из Стэнфордского университета Майкл Косински решил использовать самые современные методы, чтобы в очередной раз опровергнуть вышеописанные заблуждения. Вышло наоборот :)
Майкл разработал искусственный интеллект, который узнает ненамного менее интимную характеристику человека по его лицу — политические убеждения. Результаты последнего эксперимента были опубликованы 11 января этого года в рецензируемом журнале Nature Scientific Reports.
Алгоритм проверили более чем на миллионе фотографий реальных людей из США, Канады и Великобритании. Изображения брали из социальных сетей и с сайтов знакомств, а политические убеждения оценивали по бинарной системе «либерал — консерватор». Точность алгоритма оказалась в диапазоне 66-72%. Нейросеть анализировала только овал лица, все остальные детали с изображения отсеивались. Таким образом устранялось влияние посторонних предметов в кадре и окружающей обстановки.
На первый взгляд может показаться, что результаты алгоритма не особо впечатляющие. Но человек в аналогичной ситуации справляется существенно хуже: всего на 55%, что незначительно эффективнее подбрасывания монеты.
Косински предпринял несколько попыток определить хотя бы некоторые из параметров, на которые опирался AI. Он безрезультатно проверил множество признаков: цвет волос на лице, прямой взгляд в камеру у человека или он прячет глаза, различные эмоции. Простые, понятные и привычные людям критерии не сработали: судя по всему, нейросеть нашла что-то еще.
Основной гипотезой сейчас является тот факт, что социальные факторы, отражающиеся в нашей культуре, накладывают отпечаток на внешность. С этим "черным ящиком" нейросети еще предстоит разбираться, но уже сейчас видно, как эта новая модель может использоваться при подготовке к выборам в США и не только.
{kind=link}
Фотонные нейроморфные вычисления
Группа ученых, включая достаточно известного в своих кругах профессора Дэвида Райта из Университета Эксетер (University of Exeter), исследовала потенциал компьютерных систем, используя фотонику вместо традиционной электроники.
Статья опубликована недавно в журнале Nature Photonics.
Исследование сосредоточено на потенциальных решениях одной из самых насущных компьютерных проблем в мире - разработка технологии для быстрой и энергоэффективной обработки данных.
Современные компьютеры основаны на архитектуре фон Неймана, в которой быстрый центральный процессор (ЦП) физически отделен от гораздо более медленной памяти, а значит от программ и данных.
Это означает, что скорость вычислений ограничена, а мощность тратится впустую из-за необходимости непрерывной передачи данных в процессор из память и в память из процессора через электрические соединения с ограниченной пропускной способностью и энергоэффективностью, известные как узкое место фон Неймана.
В результате было подсчитано, что в среднем более 50% мощности современных вычислительных систем тратится впустую просто на перемещение данных.
Нашумевшая “система на чипе” M1 на базе архитектуры ARM от Apple показывает насколько глубокий застой установился в развитии компьютерных технологий за последние 10 лет и своим прорывом в энергоэффективности дает надежду на качественный скачок. Несмотря на восторженные отзывы даже отчаянных скептиков в М1 всего лишь объединены память и ЦП на одном чипе и тем самым уменьшены потери скорости передачи данных. Но это все еще физически разделённые ЦП и память, хоть и установленные в непосредственной близости, а сам подход имеет коммерческое использование со времен первых смартфонов.
Профессор Дэвид Райт из инженерного факультета и один из соавторов исследования попытался описать ситуацию: «Очевидно, что необходим новый подход - такой, который может объединить основные задачи обработки информации: вычисления и память, тот, который может напрямую включать в аппаратные средства способность учиться, адаптироваться и развиваться, и тот, который устраняет энергозатратные и ограничивающие скорость электрических соединений».
Фотонные нейроморфные вычисления - один из таких подходов. Здесь сигналы передаются и обрабатываются с использованием света, а не электронов, что дает доступ к гораздо большей полосе пропускания (потенциально - скорости процессора) и значительно сокращает потери энергии.
Более того, исследователи пытаются сделать само вычислительное оборудование изоморфным с биологической системой обработки (а это наш мозг), разрабатывая устройства, которые имитируют основные функции нейронов мозга и синапсов, а затем соединяют их вместе в сети, которые должны обеспечить быструю, параллельную, адаптивную обработку для приложений искусственного интеллекта и машинного обучения.
Группа ученых, включая достаточно известного в своих кругах профессора Дэвида Райта из Университета Эксетер (University of Exeter), исследовала потенциал компьютерных систем, используя фотонику вместо традиционной электроники.
Статья опубликована недавно в журнале Nature Photonics.
Исследование сосредоточено на потенциальных решениях одной из самых насущных компьютерных проблем в мире - разработка технологии для быстрой и энергоэффективной обработки данных.
Современные компьютеры основаны на архитектуре фон Неймана, в которой быстрый центральный процессор (ЦП) физически отделен от гораздо более медленной памяти, а значит от программ и данных.
Это означает, что скорость вычислений ограничена, а мощность тратится впустую из-за необходимости непрерывной передачи данных в процессор из память и в память из процессора через электрические соединения с ограниченной пропускной способностью и энергоэффективностью, известные как узкое место фон Неймана.
В результате было подсчитано, что в среднем более 50% мощности современных вычислительных систем тратится впустую просто на перемещение данных.
Нашумевшая “система на чипе” M1 на базе архитектуры ARM от Apple показывает насколько глубокий застой установился в развитии компьютерных технологий за последние 10 лет и своим прорывом в энергоэффективности дает надежду на качественный скачок. Несмотря на восторженные отзывы даже отчаянных скептиков в М1 всего лишь объединены память и ЦП на одном чипе и тем самым уменьшены потери скорости передачи данных. Но это все еще физически разделённые ЦП и память, хоть и установленные в непосредственной близости, а сам подход имеет коммерческое использование со времен первых смартфонов.
Профессор Дэвид Райт из инженерного факультета и один из соавторов исследования попытался описать ситуацию: «Очевидно, что необходим новый подход - такой, который может объединить основные задачи обработки информации: вычисления и память, тот, который может напрямую включать в аппаратные средства способность учиться, адаптироваться и развиваться, и тот, который устраняет энергозатратные и ограничивающие скорость электрических соединений».
Фотонные нейроморфные вычисления - один из таких подходов. Здесь сигналы передаются и обрабатываются с использованием света, а не электронов, что дает доступ к гораздо большей полосе пропускания (потенциально - скорости процессора) и значительно сокращает потери энергии.
Более того, исследователи пытаются сделать само вычислительное оборудование изоморфным с биологической системой обработки (а это наш мозг), разрабатывая устройства, которые имитируют основные функции нейронов мозга и синапсов, а затем соединяют их вместе в сети, которые должны обеспечить быструю, параллельную, адаптивную обработку для приложений искусственного интеллекта и машинного обучения.
Nature
Photonics for artificial intelligence and neuromorphic computing
Nature Photonics - Photonics offers an attractive platform for implementing neuromorphic computing due to its low latency, multiplexing capabilities and integrated on-chip technology.
Ученый Принстонской Лаборатории Физики Плазмы (PPPL) Министерства энергетики США (DOE), успешно применил машинное обучение вместо математической модели физической теории для прогнозирования результатов наблюдений. “Обычно в физике вы делаете наблюдения, создаете теорию, основанную на этих наблюдениях, а затем используете эту теорию для предсказания новых наблюдений”, - говорит физик Хун Чинь, автор статьи, подробно описывающей эту концепцию в Scientific Reports. “Я заменяю этот процесс своего рода черным ящиком, который может давать точные прогнозы без использования традиционной теории или закона”.
Чинь создал компьютерную программу, в которую ввел данные наблюдений за орбитами Меркурия, Венеры, Земли, Марса, Юпитера и карликовой планеты Церера. Эта программа сделала точные предсказания орбит других планет в солнечной системе без использования законов движения и гравитации Ньютона. "По сути, я обошел все фундаментальные составляющие физики. Я перехожу непосредственно от данных к данным", - говорит Чинь, "Посередине нет закона физики".
Программа не делает точных прогнозов случайно. “Хун обучил программу основополагающему принципу, используемому природой для определения динамики любой физической системы”, - прокомментировал Джошуа Берби, физик из Лос-Аламосской национальной лаборатории Министерства энергетики США, получивший докторскую степень в Принстоне под наставничеством Чинь. “Результатом является то, что сеть изучает законы движения планет после просмотра очень небольшого количества обучающих примеров. Другими словами, его код действительно «изучает» законы физики”.
Подобный процесс также проявляется в философских мысленных экспериментах, таких как "Китайская комната" Джона Сёрла. В этом случае человек, не знающий китайского, тем не менее, может «перевести» китайское предложение на английский или любой другой язык, используя набор инструкций или правил, которые заменят понимание. Мысленный эксперимент поднимает вопросы о том, что, по сути, означает понимание чего-либо вообще, и подразумевает ли понимание, что в уме происходит что-то еще, помимо следования правилам.
Чинь был в том числе вдохновлен философским мысленным экспериментом оксфордского философа Ника Бострома, согласно которому Вселенная - это компьютерная симуляция. «Если мы живем в симуляции, наш мир должен быть дискретным», - говорит Чинь. Техника черного ящика, разработанная ученым, не требует, чтобы физики буквально верили в симуляцию, хотя она и основывается на этой идее для создания программы, которая делает точные физические предсказания.
Получающийся в результате пиксельный взгляд на мир, похожий на то, что изображено в фильме «Матрица», известен как теория дискретного поля, которая рассматривает Вселенную как состоящую из отдельных частей. В то время как ученые обычно разрабатывают всеобъемлющие концепции поведения физического мира, компьютеры просто собирают набор точек данных.
Чинь и Эрик Палмердука, аспирант программы Принстонского университета по физике плазмы, сейчас разрабатывают способы использования дискретных теорий поля для предсказания поведения частиц плазмы в термоядерных экспериментах, проводимых учеными всего мира. Наиболее широко используемыми термоядерными установками являются токамаки в форме пончиков, которые удерживают плазму в мощных магнитных полях.
Термоядерный синтез - сила, которая движет Солнцем и звездами. Ученые стремятся воспроизвести термоядерный синтез на Земле, чтобы получить практически неисчерпаемый источник энергии для выработки электричества.
“В устройстве магнитного синтеза динамика плазмы сложна и масштабна, а вычислительные модели для конкретного физического процесса, который нас интересует, не всегда ясны”, - говорит Чинь. “В таких сценариях мы можем применить метод машинного обучения, который я разработал, чтобы создать дискретную теорию поля, а затем применить эту дискретную теорию поля для понимания и предсказания новых экспериментальных наблюдений”.
продолжение статьи
Чинь создал компьютерную программу, в которую ввел данные наблюдений за орбитами Меркурия, Венеры, Земли, Марса, Юпитера и карликовой планеты Церера. Эта программа сделала точные предсказания орбит других планет в солнечной системе без использования законов движения и гравитации Ньютона. "По сути, я обошел все фундаментальные составляющие физики. Я перехожу непосредственно от данных к данным", - говорит Чинь, "Посередине нет закона физики".
Программа не делает точных прогнозов случайно. “Хун обучил программу основополагающему принципу, используемому природой для определения динамики любой физической системы”, - прокомментировал Джошуа Берби, физик из Лос-Аламосской национальной лаборатории Министерства энергетики США, получивший докторскую степень в Принстоне под наставничеством Чинь. “Результатом является то, что сеть изучает законы движения планет после просмотра очень небольшого количества обучающих примеров. Другими словами, его код действительно «изучает» законы физики”.
Подобный процесс также проявляется в философских мысленных экспериментах, таких как "Китайская комната" Джона Сёрла. В этом случае человек, не знающий китайского, тем не менее, может «перевести» китайское предложение на английский или любой другой язык, используя набор инструкций или правил, которые заменят понимание. Мысленный эксперимент поднимает вопросы о том, что, по сути, означает понимание чего-либо вообще, и подразумевает ли понимание, что в уме происходит что-то еще, помимо следования правилам.
Чинь был в том числе вдохновлен философским мысленным экспериментом оксфордского философа Ника Бострома, согласно которому Вселенная - это компьютерная симуляция. «Если мы живем в симуляции, наш мир должен быть дискретным», - говорит Чинь. Техника черного ящика, разработанная ученым, не требует, чтобы физики буквально верили в симуляцию, хотя она и основывается на этой идее для создания программы, которая делает точные физические предсказания.
Получающийся в результате пиксельный взгляд на мир, похожий на то, что изображено в фильме «Матрица», известен как теория дискретного поля, которая рассматривает Вселенную как состоящую из отдельных частей. В то время как ученые обычно разрабатывают всеобъемлющие концепции поведения физического мира, компьютеры просто собирают набор точек данных.
Чинь и Эрик Палмердука, аспирант программы Принстонского университета по физике плазмы, сейчас разрабатывают способы использования дискретных теорий поля для предсказания поведения частиц плазмы в термоядерных экспериментах, проводимых учеными всего мира. Наиболее широко используемыми термоядерными установками являются токамаки в форме пончиков, которые удерживают плазму в мощных магнитных полях.
Термоядерный синтез - сила, которая движет Солнцем и звездами. Ученые стремятся воспроизвести термоядерный синтез на Земле, чтобы получить практически неисчерпаемый источник энергии для выработки электричества.
“В устройстве магнитного синтеза динамика плазмы сложна и масштабна, а вычислительные модели для конкретного физического процесса, который нас интересует, не всегда ясны”, - говорит Чинь. “В таких сценариях мы можем применить метод машинного обучения, который я разработал, чтобы создать дискретную теорию поля, а затем применить эту дискретную теорию поля для понимания и предсказания новых экспериментальных наблюдений”.
продолжение статьи
Telegraph
комментарии, выводы и философия
Такой подход поднимает вопросы о природе самой науки. Разве ученые не хотят развивать физические теории, объясняющие мир, вместо того, чтобы просто накапливать данные? Разве теории не являются фундаментальными для физики и необходимыми для объяснения и понимания…
#funky_ai
Наверняка у многих была в жизни ситуация, когда сомелье начинает рассказывать о происхождении вина, а вы ждете, когда эта ерунда закончится и вам уже нальют :)
Недавно, в журнале Scientific Reports опубликовали статью, где рассказали об обучении нейронных сетей определять, как климат, год производства и высота над морем влияют на вкус вина.
Производство вина — это сложный и многостадийный процесс. На него влияет множество факторов, таких как климат, солнечная активность, состав почвы и многие другие. Чаще всего для оценки вина используется информация о сортах винограда, местонахождении виноделен и, конечно, дате производства.
На сегодняшний день это понятие считается спорным и во многом интуитивным. Тем не менее все больше ученых пытаются доказать влияние некоторых терруарных факторов на конечный состав вина, а также провести четкую границу между природным и человеческим факторами.
Сильнее всего на внешний вид и вкусовые качества вина влияет содержание фенольных соединений: антоцианинов, флавонолов, стильбенов и разнообразных кислот на основе фенола. Некоторые из этих соединений получаются в процессе созревания винограда, а некоторые — в результате химических и биохимических процессов уже во время изготовления вина.
Группа ученых под руководством Ариэля Фонтана из Национального университета Куйо проанализировала мальбек, виноград для производства которого вырос на 23 земельных участках провинции Мендоса. Для каждого из них ученые взяли по три образца различной выдержки: 2016, 2017 и 2018 годов. В образцах определялось содержание 27 фенольных соединений с помощью жидкостной хроматографии.
В первую очередь, сравнив между собой образцы разных лет, авторы обнаружили заметную разницу в содержании фенольных примесей. Из этого они сделали вывод, что анализировать терруарные эффекты целесообразно только имея данные за несколько лет, так как с увеличением времени выдержки меняется и содержание компонентов. Это особенно важно для того, чтобы не перепутать систематические терруарные эффекты со случайными отклонениями разных сезонов.
Далее ученые использовали машинное обучение на полученном массиве данных о концентрациях фенольных соединений, чтобы попытаться отличить участки друг от друга, даже если они находятся в одной климатической зоне. За основу взяли алгоритм случайного леса из 300 деревьев. Для обучения использовали 66,6 процента исходных данных, а остальные оставили для тестирования алгоритма и построения матрицы ошибок.
Исходными данными были концентрации п-кумаровой кислоты, дельфинидин-3-О-глюкозида, кофейной кислоты, кверцетина и пеонидин-3-О-глюкозида, как основных фенольных примесей. Концентрации были измерены для каждого участка земли. Тестирование показало ошибку в 46,72 процента — это означает, что ученые научили компьютер определять место происхождения вина по его составу с точностью 53,28 процента.
Несмотря на то, что в маркетинге, происхождение вина играет одну из ключевых ролей, даже профессиональные дегустаторы не всегда справляются с тем, чтобы отличить вина из разных климатических зон. Например, недавно австралийские исследователи также заметили разницу в химическом составе вин из теплого и холодного климата. Но дегустаторы так и не смогли отличить их по вкусу.
Интересно будет посмотреть, какой результат даст AI на более весомом куске данных: действительно ли происхождение вина так важно, либо это очередной маркетинговый ход.
Всех с наступающим праздником и пейте в меру :)
Наверняка у многих была в жизни ситуация, когда сомелье начинает рассказывать о происхождении вина, а вы ждете, когда эта ерунда закончится и вам уже нальют :)
Недавно, в журнале Scientific Reports опубликовали статью, где рассказали об обучении нейронных сетей определять, как климат, год производства и высота над морем влияют на вкус вина.
Производство вина — это сложный и многостадийный процесс. На него влияет множество факторов, таких как климат, солнечная активность, состав почвы и многие другие. Чаще всего для оценки вина используется информация о сортах винограда, местонахождении виноделен и, конечно, дате производства.
На сегодняшний день это понятие считается спорным и во многом интуитивным. Тем не менее все больше ученых пытаются доказать влияние некоторых терруарных факторов на конечный состав вина, а также провести четкую границу между природным и человеческим факторами.
Сильнее всего на внешний вид и вкусовые качества вина влияет содержание фенольных соединений: антоцианинов, флавонолов, стильбенов и разнообразных кислот на основе фенола. Некоторые из этих соединений получаются в процессе созревания винограда, а некоторые — в результате химических и биохимических процессов уже во время изготовления вина.
Группа ученых под руководством Ариэля Фонтана из Национального университета Куйо проанализировала мальбек, виноград для производства которого вырос на 23 земельных участках провинции Мендоса. Для каждого из них ученые взяли по три образца различной выдержки: 2016, 2017 и 2018 годов. В образцах определялось содержание 27 фенольных соединений с помощью жидкостной хроматографии.
В первую очередь, сравнив между собой образцы разных лет, авторы обнаружили заметную разницу в содержании фенольных примесей. Из этого они сделали вывод, что анализировать терруарные эффекты целесообразно только имея данные за несколько лет, так как с увеличением времени выдержки меняется и содержание компонентов. Это особенно важно для того, чтобы не перепутать систематические терруарные эффекты со случайными отклонениями разных сезонов.
Далее ученые использовали машинное обучение на полученном массиве данных о концентрациях фенольных соединений, чтобы попытаться отличить участки друг от друга, даже если они находятся в одной климатической зоне. За основу взяли алгоритм случайного леса из 300 деревьев. Для обучения использовали 66,6 процента исходных данных, а остальные оставили для тестирования алгоритма и построения матрицы ошибок.
Исходными данными были концентрации п-кумаровой кислоты, дельфинидин-3-О-глюкозида, кофейной кислоты, кверцетина и пеонидин-3-О-глюкозида, как основных фенольных примесей. Концентрации были измерены для каждого участка земли. Тестирование показало ошибку в 46,72 процента — это означает, что ученые научили компьютер определять место происхождения вина по его составу с точностью 53,28 процента.
Несмотря на то, что в маркетинге, происхождение вина играет одну из ключевых ролей, даже профессиональные дегустаторы не всегда справляются с тем, чтобы отличить вина из разных климатических зон. Например, недавно австралийские исследователи также заметили разницу в химическом составе вин из теплого и холодного климата. Но дегустаторы так и не смогли отличить их по вкусу.
Интересно будет посмотреть, какой результат даст AI на более весомом куске данных: действительно ли происхождение вина так важно, либо это очередной маркетинговый ход.
Всех с наступающим праздником и пейте в меру :)
Nature
Terroir and vintage discrimination of Malbec wines based on phenolic composition across multiple sites in Mendoza, Argentina
Scientific Reports - Terroir and vintage discrimination of Malbec wines based on phenolic composition across multiple sites in Mendoza, Argentina
Кожа для робота
Результаты разработки нового мягкого тактильного датчика с характеристиками, сравнимыми с кожей были недавно опубликованы в научном журнале Science Robotics под названием “Мягкая магнитная кожа для тактильного восприятия сверхвысокого разрешения с силовой саморазвязкой”. Доктор Шен Яцзин, доцент кафедры биомедицинской инженерии (BME) CityU, был одним из руководителей исследования.
Основной характеристикой кожи человека является ее способность ощущать “силу сдвига”, то есть силу, которая заставляет два объекта прилипать или скользить друг по другу при контакте. Ощущая величину, направление и тонкое изменение силы сдвига, наша кожа может позволять нам стабильно удерживать объект руками и пальцами и регулировать насколько крепко мы должны его сжимать.
Чтобы имитировать эту важную особенность человеческой кожи, доктор Шен и доктор Пан Цзя, сотрудник Университета Гонконга (HKU), разработали новый мягкий тактильный датчик. Датчик имеет многослойную структуру, подобную коже человека, и включает в себя гибкую намагниченную пленку толщиной около 0,5 мм в качестве верхнего слоя. Когда на него действует внешняя сила, он может определять изменение магнитного поля из-за деформации пленки. Что еще важнее, он может автоматически декомпозировать внешнюю силу на две составляющие - нормальную (силу, приложенную перпендикулярно объекту) и поперечную силу, обеспечивая точное измерение каждой из этих двух сил соответственно.
“Важно разделить внешнюю силу, потому что каждая составляющая силы имеет собственное влияние на объект. И необходимо знать точное значение каждой составляющей силы, чтобы анализировать или контролировать стационарное или движущееся состояние объекта”, - пояснил Ян Юкан, аспирант BME и первый автор статьи.
Сенсор обладает еще одним свойством кожи человека - тактильным «сверхвысоким разрешением», которое позволяет ему определять местоположение воздействия с максимальной точностью. «Мы разработали эффективный алгоритм тактильного сверхвысокого разрешения с использованием глубокого обучения и достигли 60-кратного повышения точности локализации положения контакта, что является лучшим среди подобных методов, о которых сообщалось до сих пор», - сказал д-р Шен. Такой эффективный тактильный алгоритм сверхвысокого разрешения может помочь улучшить физическое разрешение матрицы тактильных датчиков с наименьшим количеством сенсорных блоков, тем самым уменьшая количество проводов и время, необходимое для передачи сигнала.
Установив датчик на кончиках пальцев роботизированного захвата, команда показала, что роботы могут выполнять сложные задачи. Например, робот уверенно хватал и удерживал хрупкие предметы, такие как яйцо, в то время как внешняя сила пыталась его отнять.
В будущем датчик можно легко расширить до матрицы датчиков или даже в виде непрерывной электронной оболочки, которая будет покрывать все тело робота. Чувствительность и диапазон измерения датчика можно регулировать, изменяя направление намагничивания верхнего слоя (магнитной пленки) датчика без изменения толщины датчика. Это позволяет электронной коже иметь различную чувствительность и диапазон измерения в разных частях, как у человеческой кожи.
Кроме того, процесс изготовления и калибровки датчика намного короче по сравнению с другими тактильными датчиками.
Даже при текущем уровне развития машинного обучения в общем и технологий обучения с подкреплением в частности не составит труда обучить машин сложнейшим манипуляциям практически над любыми объектами. Спектр применения безграничен - от сборки хрупких и чувствительных компонент, которая до сих пор выполняется людьми (т.е. медленно и с человеческим фактором), до сложнейших хирургических манипуляций. Как мы всегда писали - главное это данные. Благодаря новому датчику они стали доступны.
Результаты разработки нового мягкого тактильного датчика с характеристиками, сравнимыми с кожей были недавно опубликованы в научном журнале Science Robotics под названием “Мягкая магнитная кожа для тактильного восприятия сверхвысокого разрешения с силовой саморазвязкой”. Доктор Шен Яцзин, доцент кафедры биомедицинской инженерии (BME) CityU, был одним из руководителей исследования.
Основной характеристикой кожи человека является ее способность ощущать “силу сдвига”, то есть силу, которая заставляет два объекта прилипать или скользить друг по другу при контакте. Ощущая величину, направление и тонкое изменение силы сдвига, наша кожа может позволять нам стабильно удерживать объект руками и пальцами и регулировать насколько крепко мы должны его сжимать.
Чтобы имитировать эту важную особенность человеческой кожи, доктор Шен и доктор Пан Цзя, сотрудник Университета Гонконга (HKU), разработали новый мягкий тактильный датчик. Датчик имеет многослойную структуру, подобную коже человека, и включает в себя гибкую намагниченную пленку толщиной около 0,5 мм в качестве верхнего слоя. Когда на него действует внешняя сила, он может определять изменение магнитного поля из-за деформации пленки. Что еще важнее, он может автоматически декомпозировать внешнюю силу на две составляющие - нормальную (силу, приложенную перпендикулярно объекту) и поперечную силу, обеспечивая точное измерение каждой из этих двух сил соответственно.
“Важно разделить внешнюю силу, потому что каждая составляющая силы имеет собственное влияние на объект. И необходимо знать точное значение каждой составляющей силы, чтобы анализировать или контролировать стационарное или движущееся состояние объекта”, - пояснил Ян Юкан, аспирант BME и первый автор статьи.
Сенсор обладает еще одним свойством кожи человека - тактильным «сверхвысоким разрешением», которое позволяет ему определять местоположение воздействия с максимальной точностью. «Мы разработали эффективный алгоритм тактильного сверхвысокого разрешения с использованием глубокого обучения и достигли 60-кратного повышения точности локализации положения контакта, что является лучшим среди подобных методов, о которых сообщалось до сих пор», - сказал д-р Шен. Такой эффективный тактильный алгоритм сверхвысокого разрешения может помочь улучшить физическое разрешение матрицы тактильных датчиков с наименьшим количеством сенсорных блоков, тем самым уменьшая количество проводов и время, необходимое для передачи сигнала.
Установив датчик на кончиках пальцев роботизированного захвата, команда показала, что роботы могут выполнять сложные задачи. Например, робот уверенно хватал и удерживал хрупкие предметы, такие как яйцо, в то время как внешняя сила пыталась его отнять.
В будущем датчик можно легко расширить до матрицы датчиков или даже в виде непрерывной электронной оболочки, которая будет покрывать все тело робота. Чувствительность и диапазон измерения датчика можно регулировать, изменяя направление намагничивания верхнего слоя (магнитной пленки) датчика без изменения толщины датчика. Это позволяет электронной коже иметь различную чувствительность и диапазон измерения в разных частях, как у человеческой кожи.
Кроме того, процесс изготовления и калибровки датчика намного короче по сравнению с другими тактильными датчиками.
Даже при текущем уровне развития машинного обучения в общем и технологий обучения с подкреплением в частности не составит труда обучить машин сложнейшим манипуляциям практически над любыми объектами. Спектр применения безграничен - от сборки хрупких и чувствительных компонент, которая до сих пор выполняется людьми (т.е. медленно и с человеческим фактором), до сложнейших хирургических манипуляций. Как мы всегда писали - главное это данные. Благодаря новому датчику они стали доступны.
Science
Soft magnetic skin for super-resolution tactile sensing with force self-decoupling
Human skin can sense subtle changes of both normal and shear forces (i.e., self-decoupled) and perceive stimuli with finer resolution than the average spacing between mechanoreceptors (i.e., super-resolved). By contrast, existing tactile sensors for robotic…
Оценка неопределенности в машинном обучении.
Машинное обучение применяется в самых разных сферах, но в некоторых направлениях цена ошибки очень высока. К ним относятся, например, беспилотные автомобили, медицинская диагностика и финансовое прогнозирование. Неправильное предсказание модели может привести к летальному исходу или к большим финансовым потерям. Поэтому важно уметь определять, когда система ошибается или не уверена в предсказании — тогда можно провести дополнительную проверку или научить систему делать правильный прогноз с помощью активного обучения.
Для этой цели используются оценки неопределенности. Высокий уровень неопределенности говорит о том, что с большой вероятностью модель может ошибаться. Однако полезно не только знать, что модель не уверена в предсказании, но и понимать, почему она не уверена.
Есть два основных источника неопределенности: неопределенность данных (алеаторическая) и неопределенность знаний (эпистемическая).
Неопределенность данных измеряет «сложность» задачи и может быть вызвана, например, пересекающимися классами. Важно: эта неопределенность не может быть уменьшена путем сбора большего количества обучающих данных.
Неопределенность знаний возникает, когда модель получает входные данные из области, которая либо слабо охвачена обучающими данными, либо далека от них. Поскольку модель мало знает об этой области, она, скорее всего, допустит ошибку. В отличие от неопределенности данных, неопределенность знаний может быть уменьшена путем сбора большего количества обучающих данных из плохо изученных областей.
Если наша цель — обнаружить ошибки модели, то нет необходимости разделять эти две неопределенности. Но если мы хотим использовать активное обучение, нам захочется как-то оценить неопределенность знаний.
Как же можно оценить неопределенности данных и знаний? Рассмотрим на примере алгоритма CatBoost. Он основан на градиентном бустинге, хорошо работает с табличными данными и широко применяется в различных практических задачах.
В классической задаче регрессии часто оптимизируется функция потерь RMSE (Root Mean Squared Error). В CatBoost есть и другая функция потерь — RMSEWithUncertainty. Она предсказывает и ожидаемое значение таргета, и его дисперсию. Эта дисперсия и есть неопределенность данных.
А что же делать с неопределенностью знаний? Чтобы ее измерить, можно использовать ансамбль моделей и посмотреть, согласуются ли их предсказания или нет. Если предсказания согласуются — неопределенность знаний будет низкой, если же модели дают разные предсказания — высокой. Формально в качестве оценки неопределенности знаний можно взять дисперсию средних значений нескольких независимых моделей.
Как быть, если неопределенность знаний оценить хочется, а ресурсов на обучение нескольких независимых моделей нет? В этом случае помогут виртуальные ансамбли, которые тоже есть в CatBoost. Виртуальный ансамбль — это ансамбль из нескольких зависимых моделей, полученных из одной модели. Каждая модель в виртуальном ансамбле — это сумма первых нескольких деревьев обученной модели.
Подробнее о неопределенности в градиентом бустинге можно прочитать в этой статье.
А здесь вы найдете туториал с примерами расчета неопределенности в CatBoost.
Всем хорошей рабочей недели!
Машинное обучение применяется в самых разных сферах, но в некоторых направлениях цена ошибки очень высока. К ним относятся, например, беспилотные автомобили, медицинская диагностика и финансовое прогнозирование. Неправильное предсказание модели может привести к летальному исходу или к большим финансовым потерям. Поэтому важно уметь определять, когда система ошибается или не уверена в предсказании — тогда можно провести дополнительную проверку или научить систему делать правильный прогноз с помощью активного обучения.
Для этой цели используются оценки неопределенности. Высокий уровень неопределенности говорит о том, что с большой вероятностью модель может ошибаться. Однако полезно не только знать, что модель не уверена в предсказании, но и понимать, почему она не уверена.
Есть два основных источника неопределенности: неопределенность данных (алеаторическая) и неопределенность знаний (эпистемическая).
Неопределенность данных измеряет «сложность» задачи и может быть вызвана, например, пересекающимися классами. Важно: эта неопределенность не может быть уменьшена путем сбора большего количества обучающих данных.
Неопределенность знаний возникает, когда модель получает входные данные из области, которая либо слабо охвачена обучающими данными, либо далека от них. Поскольку модель мало знает об этой области, она, скорее всего, допустит ошибку. В отличие от неопределенности данных, неопределенность знаний может быть уменьшена путем сбора большего количества обучающих данных из плохо изученных областей.
Если наша цель — обнаружить ошибки модели, то нет необходимости разделять эти две неопределенности. Но если мы хотим использовать активное обучение, нам захочется как-то оценить неопределенность знаний.
Как же можно оценить неопределенности данных и знаний? Рассмотрим на примере алгоритма CatBoost. Он основан на градиентном бустинге, хорошо работает с табличными данными и широко применяется в различных практических задачах.
В классической задаче регрессии часто оптимизируется функция потерь RMSE (Root Mean Squared Error). В CatBoost есть и другая функция потерь — RMSEWithUncertainty. Она предсказывает и ожидаемое значение таргета, и его дисперсию. Эта дисперсия и есть неопределенность данных.
А что же делать с неопределенностью знаний? Чтобы ее измерить, можно использовать ансамбль моделей и посмотреть, согласуются ли их предсказания или нет. Если предсказания согласуются — неопределенность знаний будет низкой, если же модели дают разные предсказания — высокой. Формально в качестве оценки неопределенности знаний можно взять дисперсию средних значений нескольких независимых моделей.
Как быть, если неопределенность знаний оценить хочется, а ресурсов на обучение нескольких независимых моделей нет? В этом случае помогут виртуальные ансамбли, которые тоже есть в CatBoost. Виртуальный ансамбль — это ансамбль из нескольких зависимых моделей, полученных из одной модели. Каждая модель в виртуальном ансамбле — это сумма первых нескольких деревьев обученной модели.
Подробнее о неопределенности в градиентом бустинге можно прочитать в этой статье.
А здесь вы найдете туториал с примерами расчета неопределенности в CatBoost.
Всем хорошей рабочей недели!
Medium
Tutorial: Uncertainty estimation with CatBoost
Understanding why your model is uncertain and how to estimate the level of uncertainty
Красота в глазах машины
Исследователи из Университета Хельсинки и университета Копенгагена проверяли, сможет ли компьютер определить черты лица, которые мы считаем привлекательными, и на основе этого создать новые изображения, соответствующие нашим критериям. Ученые применили искусственный интеллект для интерпретации сигналов мозга, добавив модель генерации искусственных лиц. Это позволило компьютеру создавать образы, отвечающие индивидуальным предпочтениям.
"В наших предыдущих исследованиях мы разработали модели, которые могли определять и контролировать простые особенности лиц, такие как цвет волос и эмоции. Однако люди в основном не спорят с тем, что кто-то, например, блондин, а кто-то улыбается. Привлекательность - намного более сложный предмет изучения, поскольку он связан с культурными и психологическими факторами, которые, вероятно, играют бессознательную роль в наших индивидуальных предпочтениях. Действительно, нам часто очень трудно объяснить, что именно делает что-то или кого-то красивым: красота в глазах смотрящего", - говорит старший научный сотрудник и доцент Мишель Спапе с факультета психологии и логопедии Хельсинкского университета.
Исследование, объединяющее информатику и психологию, было опубликовано в феврале в журнале IEEE Transactions in Affective Computing.
Изначально исследователи дали генеративно-состязательной нейронной сети (GAN) задачу создать сотни искусственных портретов. Изображения были показаны по одному 30 добровольцам, которых попросили прометить лица, которые они находили привлекательными, в то время как их мозговые реакции регистрировались с помощью электроэнцефалографии (ЭЭГ).
"Это немного похоже на приложение для знакомств Tinder: участники смахивали вправо, когда сталкивались с привлекательным лицом. Мы измерили их немедленную реакцию мозга на изображения.” - объясняет Спапе.
Исследователи проанализировали данные ЭЭГ с помощью методов машинного обучения, подключив данные ЭЭГ к генеративной нейронной сети.
"Интерфейс мозг-компьютер, подобный этому, может интерпретировать мнения пользователей о привлекательности ряда изображений. Модель, интерпретирующая ответы мозга, и генеративная нейронная сеть, моделирующая изображения лиц, могут вместе производить совершенно новое изображение лица, объединяющее то, что нравится конкретному человеку", - говорит научный сотрудник Академии и доцент Туукка Руотсало, возглавляющий проект.
Чтобы проверить достоверность своего моделирования, исследователи создали новые портреты для каждого участника, предсказывая, какие из них они сочтут привлекательными. Двойное слепое тестирование на сопоставление показало, что новые изображения соответствуют предпочтениям испытуемых с точностью более 80%!
"Исследование демонстрирует, что мы способны генерировать изображения, соответствующие личным предпочтениям, путем подключения искусственной нейронной сети к ответам мозга. Успешная оценка привлекательности особенно важна, поскольку это такое острое психологическое свойство. Компьютерное зрение давно успешно классифицирует изображения на основе объективных паттернов. Вводя в процесс реакции мозга, мы показали, что можно выявлять и генерировать изображения на основе психологических свойств, таких как личный вкус", - объясняет Спапе.
Если это возможно в чем-то столь же личном и субъективном, как привлекательность, становится возможным изучение других когнитивных функции, таких как восприятие и принятие решений. “Возможно, мы могли бы настроить устройство на выявление стереотипов или скрытых предубеждений и начать лучше понимать индивидуальность людей", - завершает интервью Спапе.
Исследователи из Университета Хельсинки и университета Копенгагена проверяли, сможет ли компьютер определить черты лица, которые мы считаем привлекательными, и на основе этого создать новые изображения, соответствующие нашим критериям. Ученые применили искусственный интеллект для интерпретации сигналов мозга, добавив модель генерации искусственных лиц. Это позволило компьютеру создавать образы, отвечающие индивидуальным предпочтениям.
"В наших предыдущих исследованиях мы разработали модели, которые могли определять и контролировать простые особенности лиц, такие как цвет волос и эмоции. Однако люди в основном не спорят с тем, что кто-то, например, блондин, а кто-то улыбается. Привлекательность - намного более сложный предмет изучения, поскольку он связан с культурными и психологическими факторами, которые, вероятно, играют бессознательную роль в наших индивидуальных предпочтениях. Действительно, нам часто очень трудно объяснить, что именно делает что-то или кого-то красивым: красота в глазах смотрящего", - говорит старший научный сотрудник и доцент Мишель Спапе с факультета психологии и логопедии Хельсинкского университета.
Исследование, объединяющее информатику и психологию, было опубликовано в феврале в журнале IEEE Transactions in Affective Computing.
Изначально исследователи дали генеративно-состязательной нейронной сети (GAN) задачу создать сотни искусственных портретов. Изображения были показаны по одному 30 добровольцам, которых попросили прометить лица, которые они находили привлекательными, в то время как их мозговые реакции регистрировались с помощью электроэнцефалографии (ЭЭГ).
"Это немного похоже на приложение для знакомств Tinder: участники смахивали вправо, когда сталкивались с привлекательным лицом. Мы измерили их немедленную реакцию мозга на изображения.” - объясняет Спапе.
Исследователи проанализировали данные ЭЭГ с помощью методов машинного обучения, подключив данные ЭЭГ к генеративной нейронной сети.
"Интерфейс мозг-компьютер, подобный этому, может интерпретировать мнения пользователей о привлекательности ряда изображений. Модель, интерпретирующая ответы мозга, и генеративная нейронная сеть, моделирующая изображения лиц, могут вместе производить совершенно новое изображение лица, объединяющее то, что нравится конкретному человеку", - говорит научный сотрудник Академии и доцент Туукка Руотсало, возглавляющий проект.
Чтобы проверить достоверность своего моделирования, исследователи создали новые портреты для каждого участника, предсказывая, какие из них они сочтут привлекательными. Двойное слепое тестирование на сопоставление показало, что новые изображения соответствуют предпочтениям испытуемых с точностью более 80%!
"Исследование демонстрирует, что мы способны генерировать изображения, соответствующие личным предпочтениям, путем подключения искусственной нейронной сети к ответам мозга. Успешная оценка привлекательности особенно важна, поскольку это такое острое психологическое свойство. Компьютерное зрение давно успешно классифицирует изображения на основе объективных паттернов. Вводя в процесс реакции мозга, мы показали, что можно выявлять и генерировать изображения на основе психологических свойств, таких как личный вкус", - объясняет Спапе.
Если это возможно в чем-то столь же личном и субъективном, как привлекательность, становится возможным изучение других когнитивных функции, таких как восприятие и принятие решений. “Возможно, мы могли бы настроить устройство на выявление стереотипов или скрытых предубеждений и начать лучше понимать индивидуальность людей", - завершает интервью Спапе.
Технологии распознавания лиц - 43 года.
Исследователи института искусственного интеллекта AI Now провели исторический анализ более 100 датасетов, которые были собраны для обучения систем распознавания лиц за 43 года развития технологии.
Ниже приведем 8 ключевых деталей и вех в развитии технологии
Эффективность распознавания лиц в «лабораторных» условиях и в реальной жизни сильно различается
Одним из основных вопросов остается то, почему в системах, распознающих лица почти с безупречной точностью на тестовых заданиях, появляется столько «косяков», когда их внедряют на практике.
К примеру, Транспортное управление Нью-Йорка несколько лет назад приостановило развёртывание пилотного проекта по распознаванию лиц, потому что система ошибалась в 100% случаев. Кроме того, уже доказано, что технология хуже идентифицирует темнокожих людей - недавно из-за такой ошибки арестовали трёх невинных афроамериканцев.
Бум в развитии технологии произошёл благодаря американскому Минобороны
Разработка распознавания лиц начиналась в научных кругах и получила большой толчок в 1996 году, когда Министерство обороны и Национальный институт стандартов и технологий США выделили $6,5 млн на сбор крупнейшего на этот момент датасета. Технология интересовала правительство, поскольку в отличие от дактилоскопии не требовала активного участия граждан и могла пригодиться для слежки за населением.
На ранних этапах для наполнения датасетов проводились специальные фотосессии. Этим обусловлены большие недостатки систем распознавания
До середины «нулевых» исследователи собирали базы лиц, поводя портретные фотосессии с приглашёнными людьми. Поскольку именно они легли в основу некоторых ключевых современных технологий распознавания лиц, последние унаследовали кое-какие их недостатки. В частности, состав участников фотосъёмок был довольно однородным, а искусственная обстановка в точности не отражала реальные условия внешнего мира.
Когда фотосессий стало мало, исследователи просто пошли в Google и перестали спрашивать разрешение у людей
В 2007 году появился датасет под названием Labeled Faces in the Wild — в него вошли изображения из Google, Flickr, YouTube и прочих хранилищ картинок в интернете, в том числе фото детей. Это, с одной стороны, расширяло многообразие и репрезентативность данных, но, с другой, нарушало право на неприкосновенность частной жизни людей, которые были на них запечатлены.
Facebook спровоцировали следующий бум...
Переломным моментом для технологии стал анонс датасета DeepFace компанией Facebook в 2014 году. Facebook показали, что с помощью базы миллионов фотографий можно создавать нейросети, которые намного превосходили существовавшие тогда системы распознавания лиц, а метод под названием «глубокое обучение» стал краеугольным камнем технологии.
…наплевав на приватность пользователей
Датасет DeepFace лёг в основу функции, которая угадывала и предлагала пользователям отмечать людей на сделанных ими фотографиях. Пользователи помогали улучшить систему, подтверждая или отклоняя метки. Причём функция была включена по умолчанию и её нужно было отключать вручную.
Технология распознавания лиц обучалась на лицах 17,7 млн людей. И это — только публичные датасеты
На самом деле неизвестно, сколько не подозревающих об этом людей и кто именно стали «донорами» фотографий для разработчиков технологий распознавания лиц.
Сферы применения распознавания лиц варьируются от видеонаблюдения до таргетированной рекламы
Изначально технологию поддерживали правительства, поскольку она могла служить для охраны правопорядка и расследования преступлений. Amazon, например, предоставляет полиции свою платформу машинного зрения Rekognition, причём сколько полицейских управлений пользуется ею, компания не раскрывает.
Помимо этого, на основе распознавания лиц разрабатываются системы для анализа настроения покупателей, а также отслеживания и лучшего понимания потенциальных клиентов.
Учитывая экспоненциальный рост технологических возможностей и мощностей, можно только представить, каким будет подобный отчет через следующие 43 года :)
Исследователи института искусственного интеллекта AI Now провели исторический анализ более 100 датасетов, которые были собраны для обучения систем распознавания лиц за 43 года развития технологии.
Ниже приведем 8 ключевых деталей и вех в развитии технологии
Эффективность распознавания лиц в «лабораторных» условиях и в реальной жизни сильно различается
Одним из основных вопросов остается то, почему в системах, распознающих лица почти с безупречной точностью на тестовых заданиях, появляется столько «косяков», когда их внедряют на практике.
К примеру, Транспортное управление Нью-Йорка несколько лет назад приостановило развёртывание пилотного проекта по распознаванию лиц, потому что система ошибалась в 100% случаев. Кроме того, уже доказано, что технология хуже идентифицирует темнокожих людей - недавно из-за такой ошибки арестовали трёх невинных афроамериканцев.
Бум в развитии технологии произошёл благодаря американскому Минобороны
Разработка распознавания лиц начиналась в научных кругах и получила большой толчок в 1996 году, когда Министерство обороны и Национальный институт стандартов и технологий США выделили $6,5 млн на сбор крупнейшего на этот момент датасета. Технология интересовала правительство, поскольку в отличие от дактилоскопии не требовала активного участия граждан и могла пригодиться для слежки за населением.
На ранних этапах для наполнения датасетов проводились специальные фотосессии. Этим обусловлены большие недостатки систем распознавания
До середины «нулевых» исследователи собирали базы лиц, поводя портретные фотосессии с приглашёнными людьми. Поскольку именно они легли в основу некоторых ключевых современных технологий распознавания лиц, последние унаследовали кое-какие их недостатки. В частности, состав участников фотосъёмок был довольно однородным, а искусственная обстановка в точности не отражала реальные условия внешнего мира.
Когда фотосессий стало мало, исследователи просто пошли в Google и перестали спрашивать разрешение у людей
В 2007 году появился датасет под названием Labeled Faces in the Wild — в него вошли изображения из Google, Flickr, YouTube и прочих хранилищ картинок в интернете, в том числе фото детей. Это, с одной стороны, расширяло многообразие и репрезентативность данных, но, с другой, нарушало право на неприкосновенность частной жизни людей, которые были на них запечатлены.
Facebook спровоцировали следующий бум...
Переломным моментом для технологии стал анонс датасета DeepFace компанией Facebook в 2014 году. Facebook показали, что с помощью базы миллионов фотографий можно создавать нейросети, которые намного превосходили существовавшие тогда системы распознавания лиц, а метод под названием «глубокое обучение» стал краеугольным камнем технологии.
…наплевав на приватность пользователей
Датасет DeepFace лёг в основу функции, которая угадывала и предлагала пользователям отмечать людей на сделанных ими фотографиях. Пользователи помогали улучшить систему, подтверждая или отклоняя метки. Причём функция была включена по умолчанию и её нужно было отключать вручную.
Технология распознавания лиц обучалась на лицах 17,7 млн людей. И это — только публичные датасеты
На самом деле неизвестно, сколько не подозревающих об этом людей и кто именно стали «донорами» фотографий для разработчиков технологий распознавания лиц.
Сферы применения распознавания лиц варьируются от видеонаблюдения до таргетированной рекламы
Изначально технологию поддерживали правительства, поскольку она могла служить для охраны правопорядка и расследования преступлений. Amazon, например, предоставляет полиции свою платформу машинного зрения Rekognition, причём сколько полицейских управлений пользуется ею, компания не раскрывает.
Помимо этого, на основе распознавания лиц разрабатываются системы для анализа настроения покупателей, а также отслеживания и лучшего понимания потенциальных клиентов.
Учитывая экспоненциальный рост технологических возможностей и мощностей, можно только представить, каким будет подобный отчет через следующие 43 года :)
"Внутренности" трансформера
#NaturalLanguageProcessing
Сегодня начинаем цикл статей о современных языковых моделях - “трансформерах” - которые позволяют эффективно решать различные проблемы обработки естественного языка, от классификации текстов до генерации речи. Мы уже неоднократно про них писали, но в этом цикле попробуем писать во-первых максимально просто, а во-вторых максимально конкретно, не напуская тумана. Насколько это конечно возможно по отношению к такой сложной теме.
Сегодня поговорим о том, из чего состоит обученный трансформер. Почти вся эта информация относится и к моделям, предшествовавшим трансформерам, но так как сейчас трансформеры доминируют, мы будем писать в применении к ним.
В основе любой языковой модели, включая трансформеры, лежит вокабуляр – набор слов, который модель “знает”. Для современных трансформеров это обычно несколько десятков тысяч слов. При этом классическая проблема слов вне вокабуляра ( “out of vocabulary words”) все равно остается – какие-то слова трансформеры не знают или могут не узнать при нестандартном написании. “Слово” в данном случае употребляется расширительно, в вокабуляр входят и другие вещи (знаки препинания, эмодзи). Каждому слову вокабуляра сопоставлен его уникальный индекс (как правило, от нуля до самого последнего слова).
Следующий стандартный элемент трансфомеров – токенизатор. Токенизация (разбиение текста на слова и знаки препинания) – классический этап подготовки текстов к работе (“препроцессинга”). В теории токенизацию можно отделить от собственно трансформера и проводить другой библиотекой или методом. На практике это не так и все трансформеры пользуются своим родным токенизатором. Дело в том, что у каждого есть свои особенности, как они проводят разбиение. Например, токенизатор GPT-2 уходит на уровень ниже словесного – то есть разбивает некоторые слова на составные части. Использование неродного токенизатора приведет к неоптимальному разбиению и большим потерям точности модели.
Токенизатор и вокабуляр неразрывно связаны – токенизация всегда происходит только по словам из вокабуляра. Кроме того, к токенизаторам обычно относятся методы перевода токенов в индексы и наоборот. Это рутинные крайне распространенные операции, которые приходится производить при решении почти любой задачи обработки языка.
Перейдем к более интересному, векторам. О векторизации мы много раз говорили – чтобы “скормить” какой-либо текст машине, он должен иметь векторный вид. Трансформеры хранят векторы, соответствующие каждому слову вокабуляра. Все они имеют одинаковый размер, зависящий от трансформера или модификации (многие популярные трансформеры имеют разновидности с размерностью 512, 768 и 1024).
С помощью одних только векторов можно решать некоторые практические задачи. Самый простой пример – установление близости двух текстов. Каждый из них нужно векторизовать – это делается по набору векторов слов, входящих в тексты. Дальше можно использовать одну из мер расстояния между векторами (Эвклидово, косинусное, и.т.д.). Если расстояние ниже какого-то критического значения, значит тексты близки по смыслу.
Наконец, самый главный элемент трансформера – собственно модель или иными словами Искусственный интеллект. Модели трансформеров очень велики, состоят из большого количества слоев, в каждом из которых множество нейронов. Общее количество параметров измеряется десятками и даже сотнями миллионов. В следующих постах цикла мы разберем несколько популярных архитектур трансформеров.
В заключение сегодняшнего поста только скажем, что трансформеры первоначально обучаются на очень базовых задачах (чаще всего угадывании следующего либо спрятанного слова в тексте). Для решения практической задачи их дообучают. Таким образом, бывает доступно несколько модификаций одного и того же трансформера. Например, одна модификация для классификации, другая для суммаризации, а третья для ответов на вопросы.
#NaturalLanguageProcessing
Сегодня начинаем цикл статей о современных языковых моделях - “трансформерах” - которые позволяют эффективно решать различные проблемы обработки естественного языка, от классификации текстов до генерации речи. Мы уже неоднократно про них писали, но в этом цикле попробуем писать во-первых максимально просто, а во-вторых максимально конкретно, не напуская тумана. Насколько это конечно возможно по отношению к такой сложной теме.
Сегодня поговорим о том, из чего состоит обученный трансформер. Почти вся эта информация относится и к моделям, предшествовавшим трансформерам, но так как сейчас трансформеры доминируют, мы будем писать в применении к ним.
В основе любой языковой модели, включая трансформеры, лежит вокабуляр – набор слов, который модель “знает”. Для современных трансформеров это обычно несколько десятков тысяч слов. При этом классическая проблема слов вне вокабуляра ( “out of vocabulary words”) все равно остается – какие-то слова трансформеры не знают или могут не узнать при нестандартном написании. “Слово” в данном случае употребляется расширительно, в вокабуляр входят и другие вещи (знаки препинания, эмодзи). Каждому слову вокабуляра сопоставлен его уникальный индекс (как правило, от нуля до самого последнего слова).
Следующий стандартный элемент трансфомеров – токенизатор. Токенизация (разбиение текста на слова и знаки препинания) – классический этап подготовки текстов к работе (“препроцессинга”). В теории токенизацию можно отделить от собственно трансформера и проводить другой библиотекой или методом. На практике это не так и все трансформеры пользуются своим родным токенизатором. Дело в том, что у каждого есть свои особенности, как они проводят разбиение. Например, токенизатор GPT-2 уходит на уровень ниже словесного – то есть разбивает некоторые слова на составные части. Использование неродного токенизатора приведет к неоптимальному разбиению и большим потерям точности модели.
Токенизатор и вокабуляр неразрывно связаны – токенизация всегда происходит только по словам из вокабуляра. Кроме того, к токенизаторам обычно относятся методы перевода токенов в индексы и наоборот. Это рутинные крайне распространенные операции, которые приходится производить при решении почти любой задачи обработки языка.
Перейдем к более интересному, векторам. О векторизации мы много раз говорили – чтобы “скормить” какой-либо текст машине, он должен иметь векторный вид. Трансформеры хранят векторы, соответствующие каждому слову вокабуляра. Все они имеют одинаковый размер, зависящий от трансформера или модификации (многие популярные трансформеры имеют разновидности с размерностью 512, 768 и 1024).
С помощью одних только векторов можно решать некоторые практические задачи. Самый простой пример – установление близости двух текстов. Каждый из них нужно векторизовать – это делается по набору векторов слов, входящих в тексты. Дальше можно использовать одну из мер расстояния между векторами (Эвклидово, косинусное, и.т.д.). Если расстояние ниже какого-то критического значения, значит тексты близки по смыслу.
Наконец, самый главный элемент трансформера – собственно модель или иными словами Искусственный интеллект. Модели трансформеров очень велики, состоят из большого количества слоев, в каждом из которых множество нейронов. Общее количество параметров измеряется десятками и даже сотнями миллионов. В следующих постах цикла мы разберем несколько популярных архитектур трансформеров.
В заключение сегодняшнего поста только скажем, что трансформеры первоначально обучаются на очень базовых задачах (чаще всего угадывании следующего либо спрятанного слова в тексте). Для решения практической задачи их дообучают. Таким образом, бывает доступно несколько модификаций одного и того же трансформера. Например, одна модификация для классификации, другая для суммаризации, а третья для ответов на вопросы.
Осторожно, опасность на дороге!
Чтобы сделать беспилотные автомобили безопасными, при разработке используются сложные модели, позволяющие автомобилям анализировать и предугадывать поведение всех участников дорожного движения. Но что произойдёт, если модели ещё неспособны справляться с некоторыми сложными или непредвиденными ситуациями?
Команда, работающая с профессором Экехардом Штайнбахом, являющегося членом совета директоров Мюнхенской школы робототехники и машинного интеллекта (MSRM), использует новый подход. Их система может извлекать уроки из ситуаций, когда тестовые автомобили с автономным вождением были доведены до предела своих возможностей в реальном дорожном движении. Это ситуации, когда водитель-человек берёт вождение на себя - либо потому, что автомобиль сигнализирует о необходимости вмешательства, либо потому, что водитель решает вмешаться из соображений безопасности.
Технология использует датчики и камеры для захвата информации об окружении и записывает данные о состоянии автомобиля, например, угол поворота рулевого колеса, дорожные условия, погода, видимость и скорость. ИИ на основе рекуррентной нейронной сети (RNN), учится распознавать закономерности. Если система обнаруживает закономерность в новой дорожной ситуации, с которой система управления не могла справиться, то есть пилот брал управление, водитель будет предупреждён о возможной опасности.
«… Большое преимущество нашей технологии: мы полностью игнорируем то, что думает автомобиль. Вместо этого, мы ограничиваемся сухими данными и ищем закономерности», - говорит Штайнбах. «Таким образом, ИИ обнаруживает потенциально критические ситуации, которые модели не в состоянии распознать или с которыми ещё никогда не сталкивались. Наша система предлагает дополнительную функцию безопасности, которая знает, когда и где у автомобилей есть слабые места».
Команда исследователей протестировала эту технологию с BMW Group и её автономными машинами на дорогах общего пользования и проанализировала около 2500 ситуаций, когда водитель должен был вмешаться. Исследование показало, что ИИ уже способен предсказывать потенциально критические ситуации с точностью выше 85 процентов - за семь секунд до их возникновения.
Как и всегда в машинном обучении для функционирования технологии необходимы большие объёмы данных. По словам Кристофера Куна, одного из авторов исследования, при большом количестве тестовых автомобилей данные были практически получены сами по себе: «Каждый раз, когда во время тест-драйва возникает потенциально критическая ситуация, мы получаем новый учебный пример". Централизованное хранилище данных позволяет каждому автомобилю учиться на всех данных, записанных по всему автопарку.
Интересно не использует ли Tesla такой подход?
Чтобы сделать беспилотные автомобили безопасными, при разработке используются сложные модели, позволяющие автомобилям анализировать и предугадывать поведение всех участников дорожного движения. Но что произойдёт, если модели ещё неспособны справляться с некоторыми сложными или непредвиденными ситуациями?
Команда, работающая с профессором Экехардом Штайнбахом, являющегося членом совета директоров Мюнхенской школы робототехники и машинного интеллекта (MSRM), использует новый подход. Их система может извлекать уроки из ситуаций, когда тестовые автомобили с автономным вождением были доведены до предела своих возможностей в реальном дорожном движении. Это ситуации, когда водитель-человек берёт вождение на себя - либо потому, что автомобиль сигнализирует о необходимости вмешательства, либо потому, что водитель решает вмешаться из соображений безопасности.
Технология использует датчики и камеры для захвата информации об окружении и записывает данные о состоянии автомобиля, например, угол поворота рулевого колеса, дорожные условия, погода, видимость и скорость. ИИ на основе рекуррентной нейронной сети (RNN), учится распознавать закономерности. Если система обнаруживает закономерность в новой дорожной ситуации, с которой система управления не могла справиться, то есть пилот брал управление, водитель будет предупреждён о возможной опасности.
«… Большое преимущество нашей технологии: мы полностью игнорируем то, что думает автомобиль. Вместо этого, мы ограничиваемся сухими данными и ищем закономерности», - говорит Штайнбах. «Таким образом, ИИ обнаруживает потенциально критические ситуации, которые модели не в состоянии распознать или с которыми ещё никогда не сталкивались. Наша система предлагает дополнительную функцию безопасности, которая знает, когда и где у автомобилей есть слабые места».
Команда исследователей протестировала эту технологию с BMW Group и её автономными машинами на дорогах общего пользования и проанализировала около 2500 ситуаций, когда водитель должен был вмешаться. Исследование показало, что ИИ уже способен предсказывать потенциально критические ситуации с точностью выше 85 процентов - за семь секунд до их возникновения.
Как и всегда в машинном обучении для функционирования технологии необходимы большие объёмы данных. По словам Кристофера Куна, одного из авторов исследования, при большом количестве тестовых автомобилей данные были практически получены сами по себе: «Каждый раз, когда во время тест-драйва возникает потенциально критическая ситуация, мы получаем новый учебный пример". Централизованное хранилище данных позволяет каждому автомобилю учиться на всех данных, записанных по всему автопарку.
Интересно не использует ли Tesla такой подход?
Трудности перевода
#NaturalLanguageProcessing
В недавнем посте мы начали серию публикаций про трансформеры и пообещали рассказать о популярных архитектурах. Сегодня начнем с классического варианта трансформации последовательности слов в другую последовательность (“sequence-to-sequence”) - рекуррентной нейронной сети. Самое очевидное применение данной технологии – машинный перевод, но есть и другие (суммаризация, ответы на вопросы, и.т.д.). Мы будем основываться на машинном переводе, так как это он позволяет объяснить концепции наиболее наглядно.
Основа архитектуры – наличие двух модулей, энкодера и декодера. Задача энкодера - “понять” текст на одном языке, то есть получить компактное представление смысла изначальной фразы. Получив данное представление, декодер формирует фразу, наиболее близкую к данному смыслу, на другом языке.
Рассмотрим детально, что же происходит в языковой модели, которая получила на входе фразу “Мой отец служил на флоте” и переводит ее на английский. Энкодер получает слова последовательно, начиная с первого (в этом смысл “рекурентной” сети). Как мы уже неоднократно говорили, для того, чтобы это было возможно, сначала строчку нужно собственно разбить на слова (токены), а потом представить каждое слово в виде векторов. И только потом энкодер начинает обрабатывать эти векторы.
Обработав первое слово, энкодер получает результат – “состояние”. Так как оно не финальное – работа не закончена – это состояние “скрыто”, то есть находится внутри сети и по умолчанию пользователь его никогда не узнает. После этого энкодер получает второе слово для обработки. При этом он будет ее проводить с учетом своего текущего состояния (результата обработки первого слова). То есть когда он получит слово “отец”, он уже будет понимать, что это не какой-то абстрактный отец, а “мой отец”.
Фактически скрытое состояние представляет собой контекст, в котором обрабатывается слово. По окончании обработки второго слова скрытое состояние будет включать информацию о словах “мой” и “отец”, и модель будет учитывать ее при обработке слова “служил”. Так будет продолжаться до тех пор, пока энкодер не обработает последнее слово в предложении и не получит последнее скрытое состояние, которое будет передано декодеру.
Декодер также представляет собой рекуррентную нейронную сеть, то есть будет генерировать английские слова последовательно (“my”, “father”, “served”, etc.), на основе полученного от энкодера состояния. На каждом этапе, декодер будет определять вероятность, что каждое слово в вокабуляре является следующим. То есть после того, как он сгенерирует слово “my”, какая-то вероятность будет у слов “mother”, “dog” и даже “ball”, но если модель обучена хорошо, наибольшая вероятность будет у слова “father”, и оно и будет выбрано.
Эта архитектура появилась несколько лет назад, еще до трансформеров. И хотя на тот момент она была прорывной, скоро выявилась проблема, что она не очень хорошо работает на больших текстах. Представим себе, что она получает на вход предложение: “Мой отец, служа во флоте, совершил не один десяток кругосветных путешествий и переболел многими экзотическими болезнями”.
В данном случае, одно единственное состояние, которое получает декодер, может оказаться недостаточным для качественного перевода предложения. Контекст слишком сложен. Для решения данной проблемы, была придумана концепция “внимания” и именно она дала толчок развитию трансформеров. Но о том, что это такое, и как внимание влияет на архитектуру сети, поговорим уже в следующий раз.
#NaturalLanguageProcessing
В недавнем посте мы начали серию публикаций про трансформеры и пообещали рассказать о популярных архитектурах. Сегодня начнем с классического варианта трансформации последовательности слов в другую последовательность (“sequence-to-sequence”) - рекуррентной нейронной сети. Самое очевидное применение данной технологии – машинный перевод, но есть и другие (суммаризация, ответы на вопросы, и.т.д.). Мы будем основываться на машинном переводе, так как это он позволяет объяснить концепции наиболее наглядно.
Основа архитектуры – наличие двух модулей, энкодера и декодера. Задача энкодера - “понять” текст на одном языке, то есть получить компактное представление смысла изначальной фразы. Получив данное представление, декодер формирует фразу, наиболее близкую к данному смыслу, на другом языке.
Рассмотрим детально, что же происходит в языковой модели, которая получила на входе фразу “Мой отец служил на флоте” и переводит ее на английский. Энкодер получает слова последовательно, начиная с первого (в этом смысл “рекурентной” сети). Как мы уже неоднократно говорили, для того, чтобы это было возможно, сначала строчку нужно собственно разбить на слова (токены), а потом представить каждое слово в виде векторов. И только потом энкодер начинает обрабатывать эти векторы.
Обработав первое слово, энкодер получает результат – “состояние”. Так как оно не финальное – работа не закончена – это состояние “скрыто”, то есть находится внутри сети и по умолчанию пользователь его никогда не узнает. После этого энкодер получает второе слово для обработки. При этом он будет ее проводить с учетом своего текущего состояния (результата обработки первого слова). То есть когда он получит слово “отец”, он уже будет понимать, что это не какой-то абстрактный отец, а “мой отец”.
Фактически скрытое состояние представляет собой контекст, в котором обрабатывается слово. По окончании обработки второго слова скрытое состояние будет включать информацию о словах “мой” и “отец”, и модель будет учитывать ее при обработке слова “служил”. Так будет продолжаться до тех пор, пока энкодер не обработает последнее слово в предложении и не получит последнее скрытое состояние, которое будет передано декодеру.
Декодер также представляет собой рекуррентную нейронную сеть, то есть будет генерировать английские слова последовательно (“my”, “father”, “served”, etc.), на основе полученного от энкодера состояния. На каждом этапе, декодер будет определять вероятность, что каждое слово в вокабуляре является следующим. То есть после того, как он сгенерирует слово “my”, какая-то вероятность будет у слов “mother”, “dog” и даже “ball”, но если модель обучена хорошо, наибольшая вероятность будет у слова “father”, и оно и будет выбрано.
Эта архитектура появилась несколько лет назад, еще до трансформеров. И хотя на тот момент она была прорывной, скоро выявилась проблема, что она не очень хорошо работает на больших текстах. Представим себе, что она получает на вход предложение: “Мой отец, служа во флоте, совершил не один десяток кругосветных путешествий и переболел многими экзотическими болезнями”.
В данном случае, одно единственное состояние, которое получает декодер, может оказаться недостаточным для качественного перевода предложения. Контекст слишком сложен. Для решения данной проблемы, была придумана концепция “внимания” и именно она дала толчок развитию трансформеров. Но о том, что это такое, и как внимание влияет на архитектуру сети, поговорим уже в следующий раз.
Telegram
Новое электричество
"Внутренности" трансформера
#NaturalLanguageProcessing
Сегодня начинаем цикл статей о современных языковых моделях - “трансформерах” - которые позволяют эффективно решать различные проблемы обработки естественного языка, от классификации текстов до генерации…
#NaturalLanguageProcessing
Сегодня начинаем цикл статей о современных языковых моделях - “трансформерах” - которые позволяют эффективно решать различные проблемы обработки естественного языка, от классификации текстов до генерации…
Внимание, внимание
#NaturalLanguageProcessing
В прошлой публикации на тему Трансформеров мы описали базовую концепцию, стоящую за машинным переводом, а также другими задачами генерации текстовых строк на базе других строк (sequence-to-sequence) – энкодер “выкачивает” информацию из исходной строки и передает результат в декодер, который генерирует новую строку.
Закончили мы на том, что на длинных строках класические модели могут работать не очень хорошо. Сегодня подробней поговорим, в чем причина, и как модели были адаптированы, чтобы проблему решить.
Возьмем фразу “Иван не сразу смог забить гвоздь в брус, потому что он был кривым и ржавым”. К кому относится слово “ржавый”, Ивану, гвоздю или брусу? Для человека вопрос несложен, но для машины правильный ответ абсолютно неочевиден. Скажем, если она будет пользоваться вроде бы логичным критерием близости положения слов в строке, она решит, что к брусу. Очевидно, что такое решение с высокой вероятностью приведет к неправильной генерации новой фразы.
Чтобы правильно “понять” о чем идет речь, модель должна фокусироваться не только на самом слове, которое она обрабатывает – “ржавый”, но и на другом важном слове из строки - “гвозде”. Эта идея стоит за концепцией “внимания”, которая фактически и дала толчок к развитию современных трансформеров. Ставшая классической статья, с которой все началось, так и называется “Внимание это то, что вам нужно” (“Attention is what you need”).
Упрощенно разницу моделей с вниманием от классических моделей можно объяснить так. Старые модели в каждый момент времени смотрели только на само обрабатываемое слово. Пусть для простоты в строке всего три слова. Тогда, когда обрабатывается первое слово, вектор внимания имеет вид [1, 0, 0], а когда второе [0, 1, 0].
Модели с вниманием убрали это ограничение и позволили учитывать связи между словами. Теперь при обработке первого слова вектор внимания может иметь вид [0.6, 0.3, 0.1]. Максимальное внимание все равно на самом слове, но видно, что второе слово также очень важно, а вот третье менее. Контекст учтен намного больше.
Если вспомнить, что за каждым словом будет стоять вектор, то можно сказать, что модель будет обрабатывать средневзвешенный вектор по трем словам, где веса определены вектором внимания. Веса, в свою очередь, находятся перемножением векторов, соответствующих словам, на специальные матрицы, определенные в процессе обучения модели.
Напомним, что современные трансформеры состоят из множества слоев. С учетом внимания, каждый слой трансформера будет проводить следующие операции:
- получить входящие векторы от предыдущего слоя;
- определить внимание, которое должно быть уделено каждому полученному вектору;
- посчитать новые векторы для передачи дальше;
- передать векторы следующему слою.
Более глубоко в технические детали не пойдем, это за пределами формата поста. В будущем поговорим о практических аспектах использования и дообучения трансформеров.
#NaturalLanguageProcessing
В прошлой публикации на тему Трансформеров мы описали базовую концепцию, стоящую за машинным переводом, а также другими задачами генерации текстовых строк на базе других строк (sequence-to-sequence) – энкодер “выкачивает” информацию из исходной строки и передает результат в декодер, который генерирует новую строку.
Закончили мы на том, что на длинных строках класические модели могут работать не очень хорошо. Сегодня подробней поговорим, в чем причина, и как модели были адаптированы, чтобы проблему решить.
Возьмем фразу “Иван не сразу смог забить гвоздь в брус, потому что он был кривым и ржавым”. К кому относится слово “ржавый”, Ивану, гвоздю или брусу? Для человека вопрос несложен, но для машины правильный ответ абсолютно неочевиден. Скажем, если она будет пользоваться вроде бы логичным критерием близости положения слов в строке, она решит, что к брусу. Очевидно, что такое решение с высокой вероятностью приведет к неправильной генерации новой фразы.
Чтобы правильно “понять” о чем идет речь, модель должна фокусироваться не только на самом слове, которое она обрабатывает – “ржавый”, но и на другом важном слове из строки - “гвозде”. Эта идея стоит за концепцией “внимания”, которая фактически и дала толчок к развитию современных трансформеров. Ставшая классической статья, с которой все началось, так и называется “Внимание это то, что вам нужно” (“Attention is what you need”).
Упрощенно разницу моделей с вниманием от классических моделей можно объяснить так. Старые модели в каждый момент времени смотрели только на само обрабатываемое слово. Пусть для простоты в строке всего три слова. Тогда, когда обрабатывается первое слово, вектор внимания имеет вид [1, 0, 0], а когда второе [0, 1, 0].
Модели с вниманием убрали это ограничение и позволили учитывать связи между словами. Теперь при обработке первого слова вектор внимания может иметь вид [0.6, 0.3, 0.1]. Максимальное внимание все равно на самом слове, но видно, что второе слово также очень важно, а вот третье менее. Контекст учтен намного больше.
Если вспомнить, что за каждым словом будет стоять вектор, то можно сказать, что модель будет обрабатывать средневзвешенный вектор по трем словам, где веса определены вектором внимания. Веса, в свою очередь, находятся перемножением векторов, соответствующих словам, на специальные матрицы, определенные в процессе обучения модели.
Напомним, что современные трансформеры состоят из множества слоев. С учетом внимания, каждый слой трансформера будет проводить следующие операции:
- получить входящие векторы от предыдущего слоя;
- определить внимание, которое должно быть уделено каждому полученному вектору;
- посчитать новые векторы для передачи дальше;
- передать векторы следующему слою.
Более глубоко в технические детали не пойдем, это за пределами формата поста. В будущем поговорим о практических аспектах использования и дообучения трансформеров.
Telegram
Новое электричество
Трудности перевода
#NaturalLanguageProcessing
В недавнем посте мы начали серию публикаций про трансформеры и пообещали рассказать о популярных архитектурах. Сегодня начнем с классического варианта трансформации последовательности слов в другую последовательность…
#NaturalLanguageProcessing
В недавнем посте мы начали серию публикаций про трансформеры и пообещали рассказать о популярных архитектурах. Сегодня начнем с классического варианта трансформации последовательности слов в другую последовательность…
HTML Embed Code: