Tufa Labs опубликовала пейпер фреймворка LADDER, который дает возможность языковым моделям самостоятельно улучшать навыки решения сложных задач.
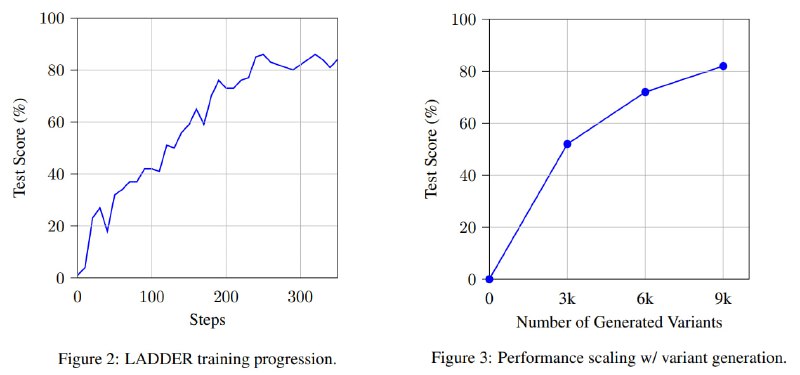
Технология имитирует человеческое обучение: ИИ разбивает проблемы на простые шаги, создаёт «учебный план» из упрощённых вариантов и постепенно наращивает мастерство решения. Например, модель Llama 3.2 с 3 млрд. параметров, изначально решавшая лишь 1% интегралов студенческого уровня, после обучения по методу LADDER достигла 82% точности.
Самые интересные результаты LADDER показал на тесте MIT Integration Bee — ежегодном соревновании по интегральному исчислению. На нем модель Qwen2.5 (7B), доработанная с помощью LADDER, набрала 73%, обойдя GPT-4o (42%) и большинство студентов, а с применением TTRL — результат вырос до 90%. Это превзошло даже показатели OpenAI o1, хотя последний не использовал числовую проверку решений.
TTRL (Test-Time Reinforcement Learning) — это метод «микрообучения», который позволяет языковым моделям адаптироваться к сложным задачам прямо во время их решения.
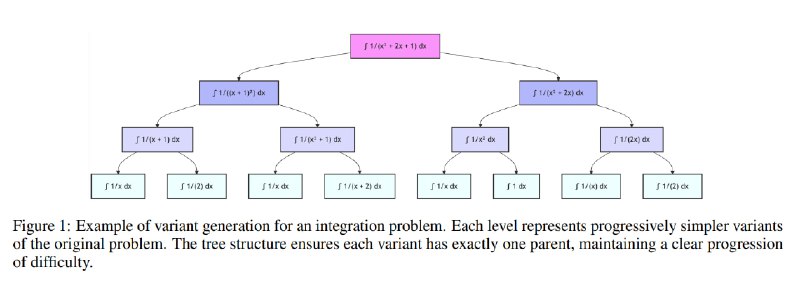
В основе LADDER - принцип рекурсивной декомпозиции: модель разбивает непосильную задачу на цепочку постепенно усложняющихся шагов, создавая собственную «учебную программу». Столкнувшись со сложным интегралом, ИИ генерирует его упрощённые версии — снижает степень полинома, убирает дробные коэффициенты или заменяет составные функции базовыми. Каждый такой вариант становится ступенью, ведущей к решению целевой задачи.
Работа фреймворка делится на три этапа:
Первый — генерация «дерева вариантов»: модель создаёт десятки модификаций задачи, ранжируя их по сложности.
Второй — верификация: каждое решение проверяется численными методами (например, сравнение значений интеграла в ключевых точках).
Третий — обучение с подкреплением: система поощряет успешные стратегии, используя баллы за правильные ответы и штрафуя за ошибки.
Дополняющее применение TTRL позволяет проводить «экспресс-тренировки» прямо во время теста: ИИ генерирует варианты конкретной задачи и адаптируется к ней за секунды, не требуя вмешательства человека.
@ai_machinelearning_big_data
#AI #ML #RL #LADDER #Paper