Create: Update:
🛡️ Fault Tolerant Llama — обучение LLM в условиях экстремальной нестабильности, без чекпоинтов
Исследовательская команда продемонстрировала обучение языковой модели в условиях, приближённых к худшему сценарию: сотни имитированных отказов происходили каждые 15 секунд, а чекпоинты полностью отключены. Цель — проверить, как себя поведёт система с полной поддержкой fault-tolerance.
🧰 Что использовалось:
• torchft — отказоустойчивая реализация DDP для PyTorch
• torchtitan — фреймворк для масштабируемого обучения с параллелизмом
• Кластер от Crusoe Cloud: 300 GPU NVIDIA L40S
• Модель: LLaMA 3, 1B параметров
🏗️ Конфигурация:
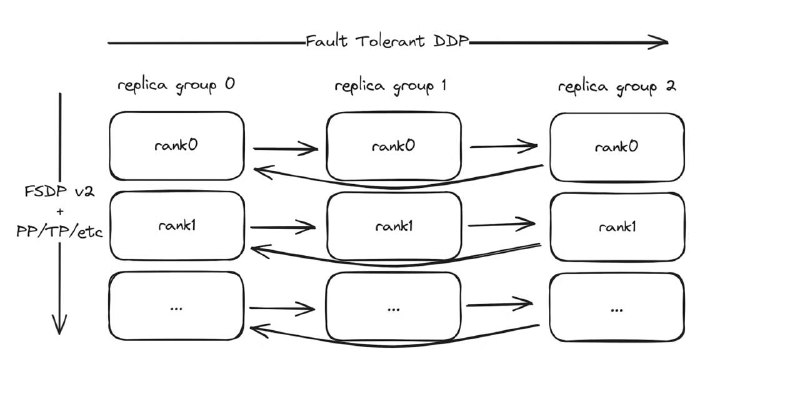
• 30 узлов × 10 GPU = 30 изолированных replica-групп
• Внутригрупповая коммуникация: NCCL
• Межгрупповая: Gloo (быстрая переинициализация, важно для отказов)
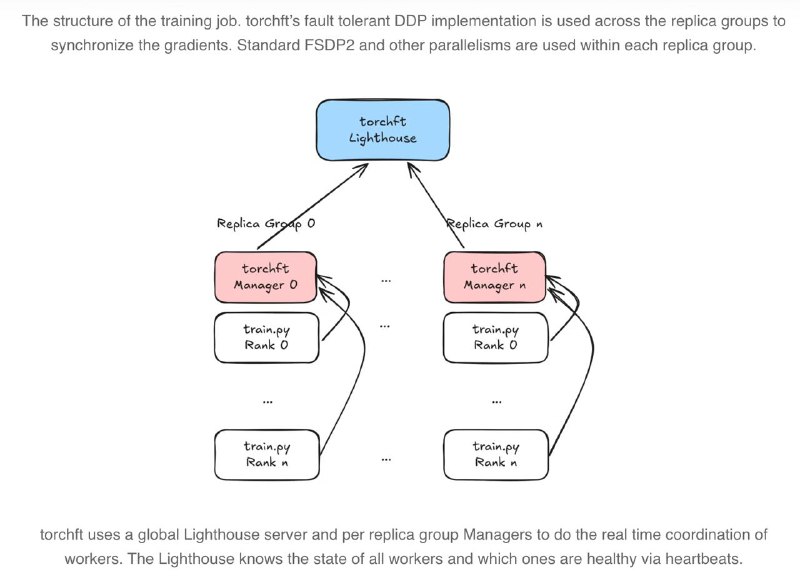
• TorchFT координирует состояние с помощью глобального Lighthouse и локальных менеджеров
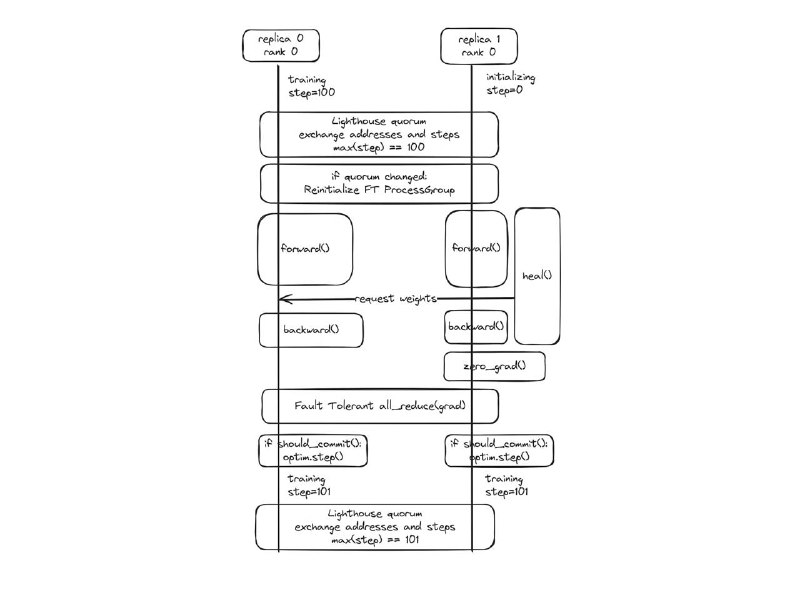
🔄 Восстановление без чекпоинтов:
Обычно сбой = загрузка чекпоинта.
Здесь: сбой = локальная перезагрузка группы, автоматическая синхронизация с другими группами.
Каждый возвращающийся узел получает актуальные веса через peer-to-peer от соседей и снова включается в обучение — без полной остановки, без потери прогресса.
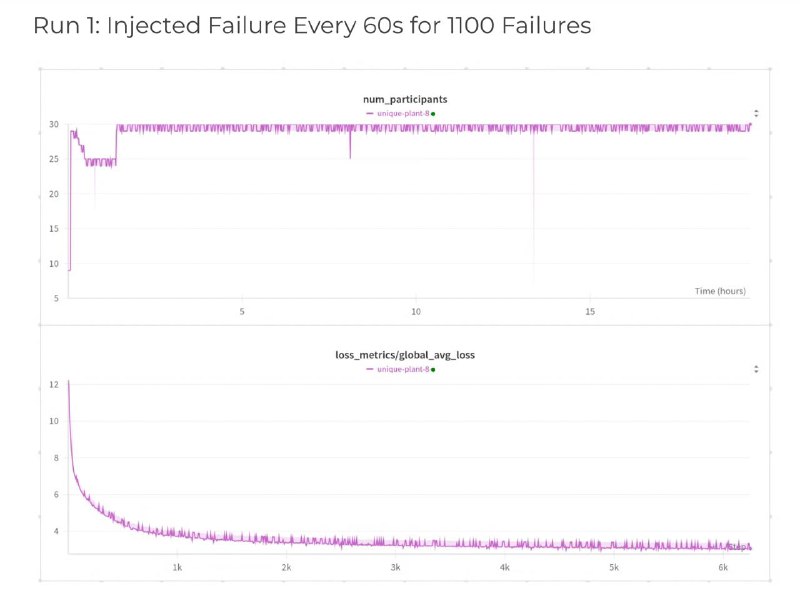
📉 Результаты:
• Более 1200 успешных восстановлений
• Обучение остаётся стабильным, модель не деградирует
• Пики на графике — это просто "возвращенцы", не сбой всей системы
📦 Почему это важно:
✔️ Подходит для нестабильных сетей и распределённых сред
✔️ Убирает зависимость от чекпоинтов
✔️ Поддерживает гибкие конфигурации: TP, PP, DiLoCo и др.
📌 Подробнее
Исследовательская команда продемонстрировала обучение языковой модели в условиях, приближённых к худшему сценарию: сотни имитированных отказов происходили каждые 15 секунд, а чекпоинты полностью отключены. Цель — проверить, как себя поведёт система с полной поддержкой fault-tolerance.
🧰 Что использовалось:
• torchft — отказоустойчивая реализация DDP для PyTorch
• torchtitan — фреймворк для масштабируемого обучения с параллелизмом
• Кластер от Crusoe Cloud: 300 GPU NVIDIA L40S
• Модель: LLaMA 3, 1B параметров
🏗️ Конфигурация:
• 30 узлов × 10 GPU = 30 изолированных replica-групп
• Внутригрупповая коммуникация: NCCL
• Межгрупповая: Gloo (быстрая переинициализация, важно для отказов)
• TorchFT координирует состояние с помощью глобального Lighthouse и локальных менеджеров
🔄 Восстановление без чекпоинтов:
Обычно сбой = загрузка чекпоинта.
Здесь: сбой = локальная перезагрузка группы, автоматическая синхронизация с другими группами.
Каждый возвращающийся узел получает актуальные веса через peer-to-peer от соседей и снова включается в обучение — без полной остановки, без потери прогресса.
📉 Результаты:
• Более 1200 успешных восстановлений
• Обучение остаётся стабильным, модель не деградирует
• Пики на графике — это просто "возвращенцы", не сбой всей системы
📦 Почему это важно:
✔️ Подходит для нестабильных сетей и распределённых сред
✔️ Убирает зависимость от чекпоинтов
✔️ Поддерживает гибкие конфигурации: TP, PP, DiLoCo и др.
📌 Подробнее

🛡️ Fault Tolerant Llama — обучение LLM в условиях экстремальной нестабильности, без чекпоинтов
Исследовательская команда продемонстрировала обучение языковой модели в условиях, приближённых к худшему сценарию: сотни имитированных отказов происходили каждые 15 секунд, а чекпоинты полностью отключены. Цель — проверить, как себя поведёт система с полной поддержкой fault-tolerance.
🧰 Что использовалось:
• torchft — отказоустойчивая реализация DDP для PyTorch
• torchtitan — фреймворк для масштабируемого обучения с параллелизмом
• Кластер от Crusoe Cloud: 300 GPU NVIDIA L40S
• Модель: LLaMA 3, 1B параметров
🏗️ Конфигурация:
• 30 узлов × 10 GPU = 30 изолированных replica-групп
• Внутригрупповая коммуникация: NCCL
• Межгрупповая: Gloo (быстрая переинициализация, важно для отказов)
• TorchFT координирует состояние с помощью глобального Lighthouse и локальных менеджеров
🔄 Восстановление без чекпоинтов:
Обычно сбой = загрузка чекпоинта.
Здесь: сбой = локальная перезагрузка группы, автоматическая синхронизация с другими группами.
Каждый возвращающийся узел получает актуальные веса через peer-to-peer от соседей и снова включается в обучение — без полной остановки, без потери прогресса.
📉 Результаты:
• Более 1200 успешных восстановлений
• Обучение остаётся стабильным, модель не деградирует
• Пики на графике — это просто "возвращенцы", не сбой всей системы
📦 Почему это важно:
✔️ Подходит для нестабильных сетей и распределённых сред
✔️ Убирает зависимость от чекпоинтов
✔️ Поддерживает гибкие конфигурации: TP, PP, DiLoCo и др.
📌 Подробнее
Исследовательская команда продемонстрировала обучение языковой модели в условиях, приближённых к худшему сценарию: сотни имитированных отказов происходили каждые 15 секунд, а чекпоинты полностью отключены. Цель — проверить, как себя поведёт система с полной поддержкой fault-tolerance.
🧰 Что использовалось:
• torchft — отказоустойчивая реализация DDP для PyTorch
• torchtitan — фреймворк для масштабируемого обучения с параллелизмом
• Кластер от Crusoe Cloud: 300 GPU NVIDIA L40S
• Модель: LLaMA 3, 1B параметров
🏗️ Конфигурация:
• 30 узлов × 10 GPU = 30 изолированных replica-групп
• Внутригрупповая коммуникация: NCCL
• Межгрупповая: Gloo (быстрая переинициализация, важно для отказов)
• TorchFT координирует состояние с помощью глобального Lighthouse и локальных менеджеров
🔄 Восстановление без чекпоинтов:
Обычно сбой = загрузка чекпоинта.
Здесь: сбой = локальная перезагрузка группы, автоматическая синхронизация с другими группами.
Каждый возвращающийся узел получает актуальные веса через peer-to-peer от соседей и снова включается в обучение — без полной остановки, без потери прогресса.
📉 Результаты:
• Более 1200 успешных восстановлений
• Обучение остаётся стабильным, модель не деградирует
• Пики на графике — это просто "возвращенцы", не сбой всей системы
📦 Почему это важно:
✔️ Подходит для нестабильных сетей и распределённых сред
✔️ Убирает зависимость от чекпоинтов
✔️ Поддерживает гибкие конфигурации: TP, PP, DiLoCo и др.
📌 Подробнее
>>Click here to continue<<
Machine learning Interview