🦙 Мультимодальная поддержка в llama.cpp (обновление)
llama.cpp теперь поддерживает мультимодальные модели с визуальным вводом!
📦 Что нового
Проект llama.cpp теперь поддерживает *мультимодальные модели* — такие как LLaVA 1.5 / 1.6, BakLLaVA, Obsidian, MobileVLM и другие, позволяя выполнять вывод, совмещающий текст и изображения локально, без облака.
🔧 Ключевые возможности
• Поддержка моделей с вводом изображения (image + text)
• Новый CLI: llama-mtmd-cli (заменяет `llava-cli`)
• Расширена совместимость: поддержка GGUF-моделей мультимодального типа
• Локальная работа на CPU и GPU без зависимости от облачных API
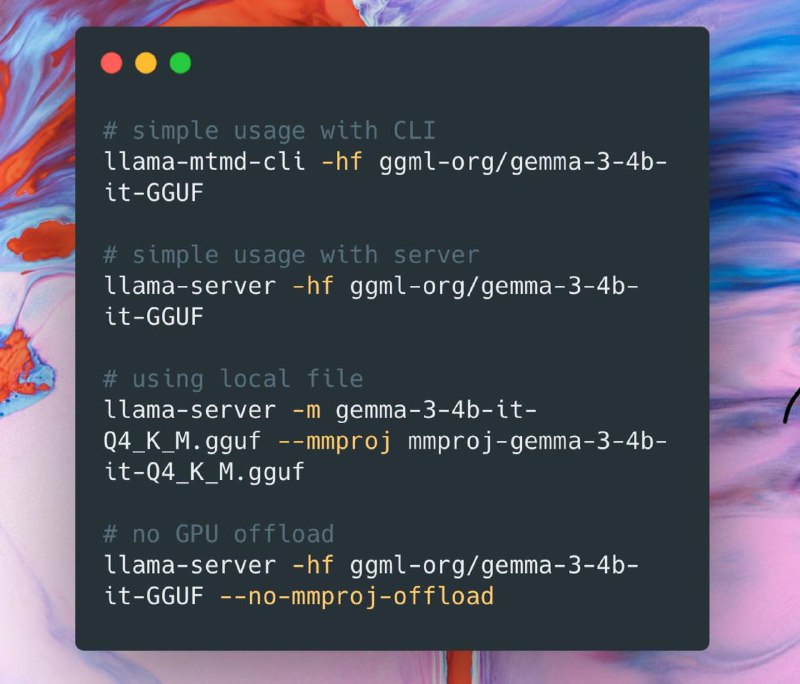
🚀 Как использовать
1. Скачай модель в формате .gguf, например LLaVA:
https://huggingface.co/liuhaotian/llava-v1.5-13b-GGUF
2. Подготовь изображение (например, `photo.jpg`)
3. Запусти CLI:
./build/bin/llama-mtmd-cli \
-m models/llava-v1.5-13b.gguf \
--image ./photo.jpg \
-p "Что изображено на фото?"
▪ GitHub
>>Click here to continue<<