Create: Update:
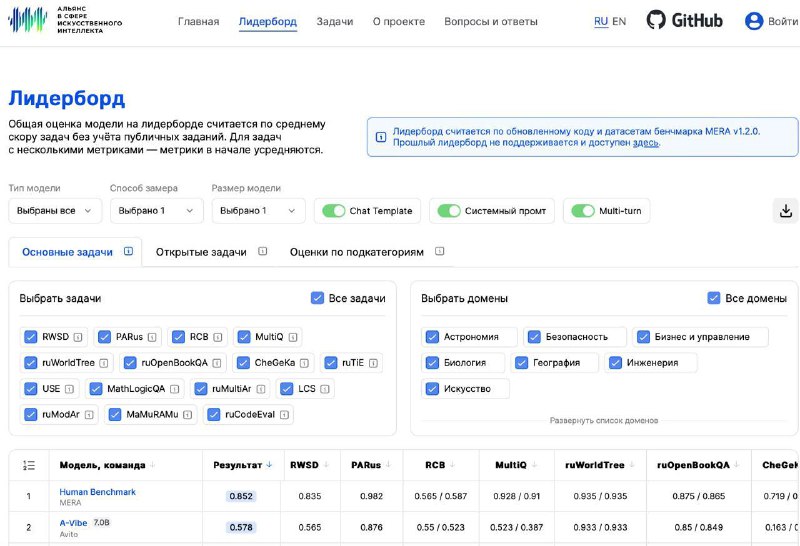
Российская языковая модель A-Vibe от Авито возглавила рейтинг легких ИИ-решений (до 10 млрд параметров) в независимом бенчмарке MERA.
Разработка команды классифайда обошла признанных зарубежных конкурентов — GPT-4o mini от OpenAI, Gemma 3 27B от Google, Claude 3.5 Haiku от Anthropic и Mistral Large.
Модель демонстрирует впечатляющие результаты работы с русским языком. В тестах генерации кода A-Vibe показала результат на 25% лучше, чем Gemini 1.5. При ведении диалогов она оказалась на 32% точнее Llama 3.1. А в анализе смысла текста превзошла Claude 3.5 Haiku на 23%.
Технические возможности A-Vibe позволяют ей одновременно обрабатывать до 32 тысяч токенов контекста. Это дает модели серьезное преимущество при работе с объемными документами и поддержании длительных осмысленных диалогов. Уже сегодня технология активно используется в сервисах Авито, помогая продавцам создавать качественные описания товаров и ускоряя коммуникацию в мессенджере платформы.
«Первое место доказывает, что оптимизированная архитектура и качественные данные могут обеспечить отличные результаты даже при небольшом размере модели. A-Vibe создавалось оптимальной по соотношению между качеством, скоростью работы и затратой ресурсов. Такой баланс позволяет обеспечивать быструю обработку запросов даже в периоды пиковой нагрузки и масштабировать технологию на всю аудиторию платформы», — отметил Андрей Рыбинцев, старший директор по данным и аналитике Авито.
До конца года Авито внедрит в свою нейросеть еще 20 сценариев, а в будущем может сделать ее общедоступной.
Познакомиться с рейтингом можно на сайте MERA. В фильтре «Размер модели» выберите «≥5B — 10B», чтобы получить рейтинг среди небольших моделей. Цифры Human Benchmark — это результат тестирования реальных людей.
Разработка команды классифайда обошла признанных зарубежных конкурентов — GPT-4o mini от OpenAI, Gemma 3 27B от Google, Claude 3.5 Haiku от Anthropic и Mistral Large.
Модель демонстрирует впечатляющие результаты работы с русским языком. В тестах генерации кода A-Vibe показала результат на 25% лучше, чем Gemini 1.5. При ведении диалогов она оказалась на 32% точнее Llama 3.1. А в анализе смысла текста превзошла Claude 3.5 Haiku на 23%.
Технические возможности A-Vibe позволяют ей одновременно обрабатывать до 32 тысяч токенов контекста. Это дает модели серьезное преимущество при работе с объемными документами и поддержании длительных осмысленных диалогов. Уже сегодня технология активно используется в сервисах Авито, помогая продавцам создавать качественные описания товаров и ускоряя коммуникацию в мессенджере платформы.
«Первое место доказывает, что оптимизированная архитектура и качественные данные могут обеспечить отличные результаты даже при небольшом размере модели. A-Vibe создавалось оптимальной по соотношению между качеством, скоростью работы и затратой ресурсов. Такой баланс позволяет обеспечивать быструю обработку запросов даже в периоды пиковой нагрузки и масштабировать технологию на всю аудиторию платформы», — отметил Андрей Рыбинцев, старший директор по данным и аналитике Авито.
До конца года Авито внедрит в свою нейросеть еще 20 сценариев, а в будущем может сделать ее общедоступной.
Познакомиться с рейтингом можно на сайте MERA. В фильтре «Размер модели» выберите «≥5B — 10B», чтобы получить рейтинг среди небольших моделей. Цифры Human Benchmark — это результат тестирования реальных людей.

Российская языковая модель A-Vibe от Авито возглавила рейтинг легких ИИ-решений (до 10 млрд параметров) в независимом бенчмарке MERA.
Разработка команды классифайда обошла признанных зарубежных конкурентов — GPT-4o mini от OpenAI, Gemma 3 27B от Google, Claude 3.5 Haiku от Anthropic и Mistral Large.
Модель демонстрирует впечатляющие результаты работы с русским языком. В тестах генерации кода A-Vibe показала результат на 25% лучше, чем Gemini 1.5. При ведении диалогов она оказалась на 32% точнее Llama 3.1. А в анализе смысла текста превзошла Claude 3.5 Haiku на 23%.
Технические возможности A-Vibe позволяют ей одновременно обрабатывать до 32 тысяч токенов контекста. Это дает модели серьезное преимущество при работе с объемными документами и поддержании длительных осмысленных диалогов. Уже сегодня технология активно используется в сервисах Авито, помогая продавцам создавать качественные описания товаров и ускоряя коммуникацию в мессенджере платформы.
«Первое место доказывает, что оптимизированная архитектура и качественные данные могут обеспечить отличные результаты даже при небольшом размере модели. A-Vibe создавалось оптимальной по соотношению между качеством, скоростью работы и затратой ресурсов. Такой баланс позволяет обеспечивать быструю обработку запросов даже в периоды пиковой нагрузки и масштабировать технологию на всю аудиторию платформы», — отметил Андрей Рыбинцев, старший директор по данным и аналитике Авито.
До конца года Авито внедрит в свою нейросеть еще 20 сценариев, а в будущем может сделать ее общедоступной.
Познакомиться с рейтингом можно на сайте MERA. В фильтре «Размер модели» выберите «≥5B — 10B», чтобы получить рейтинг среди небольших моделей. Цифры Human Benchmark — это результат тестирования реальных людей.
Разработка команды классифайда обошла признанных зарубежных конкурентов — GPT-4o mini от OpenAI, Gemma 3 27B от Google, Claude 3.5 Haiku от Anthropic и Mistral Large.
Модель демонстрирует впечатляющие результаты работы с русским языком. В тестах генерации кода A-Vibe показала результат на 25% лучше, чем Gemini 1.5. При ведении диалогов она оказалась на 32% точнее Llama 3.1. А в анализе смысла текста превзошла Claude 3.5 Haiku на 23%.
Технические возможности A-Vibe позволяют ей одновременно обрабатывать до 32 тысяч токенов контекста. Это дает модели серьезное преимущество при работе с объемными документами и поддержании длительных осмысленных диалогов. Уже сегодня технология активно используется в сервисах Авито, помогая продавцам создавать качественные описания товаров и ускоряя коммуникацию в мессенджере платформы.
«Первое место доказывает, что оптимизированная архитектура и качественные данные могут обеспечить отличные результаты даже при небольшом размере модели. A-Vibe создавалось оптимальной по соотношению между качеством, скоростью работы и затратой ресурсов. Такой баланс позволяет обеспечивать быструю обработку запросов даже в периоды пиковой нагрузки и масштабировать технологию на всю аудиторию платформы», — отметил Андрей Рыбинцев, старший директор по данным и аналитике Авито.
До конца года Авито внедрит в свою нейросеть еще 20 сценариев, а в будущем может сделать ее общедоступной.
Познакомиться с рейтингом можно на сайте MERA. В фильтре «Размер модели» выберите «≥5B — 10B», чтобы получить рейтинг среди небольших моделей. Цифры Human Benchmark — это результат тестирования реальных людей.
>>Click here to continue<<
Machine learning Interview