SakanaAI опять светятся с интересной статьей: они предлагают новый способ обучать модели ризонингу
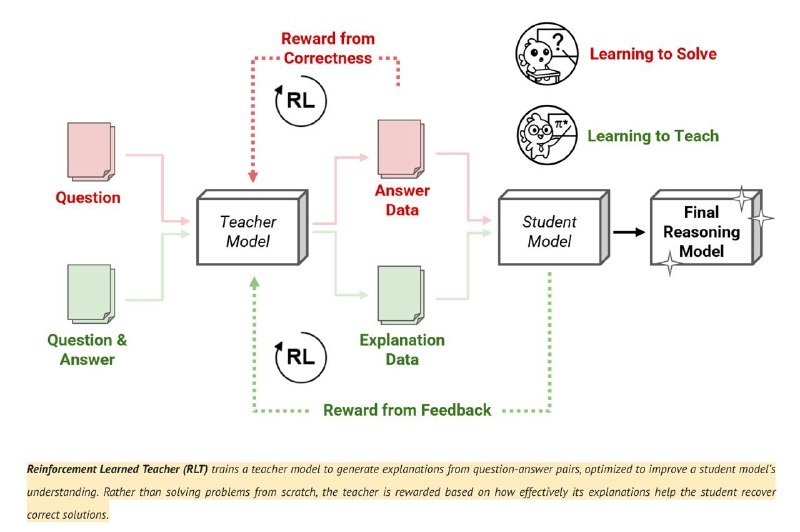
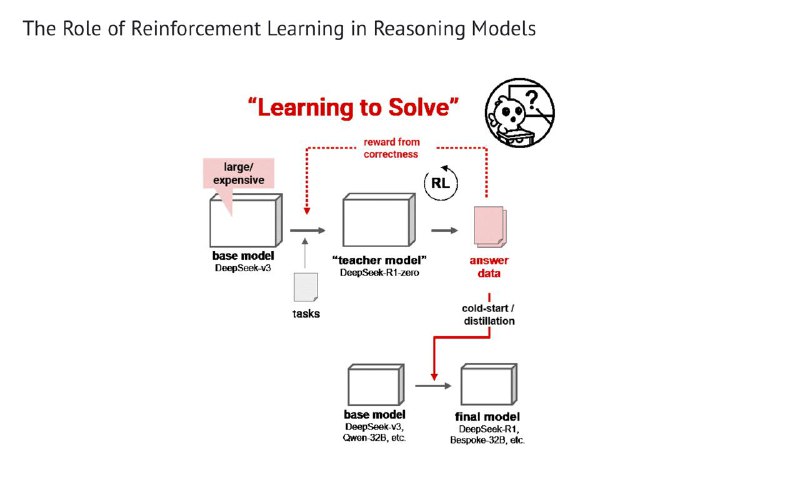
Модели умеют размышлять благодаря обучению с подкреплением. Обычно это выглядит так: модель учится решать сложные задачи, рассуждая, и получает вознаграждение, если приходит к правильному ответу. При этом часто после этого знания такой модели-учителя используются (дистилляция или cold start) для обучения модели-ученика, которая и становится конечным продуктом. Так было, например, с R1.
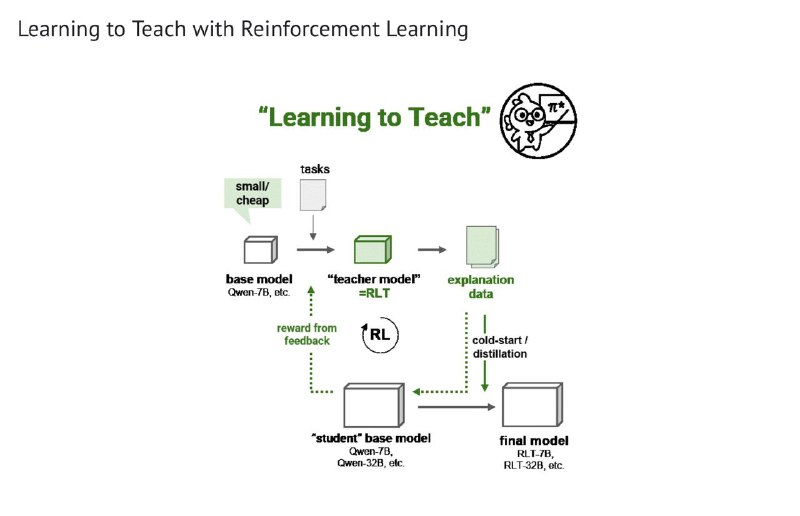
Sakana же предлагают обучать модель-учителя непосредственно учить других, вместо того, чтобы выучивать что-то самой:
Во-первых, это получается быстрее и дешевле, потому что в качестве учителя уже не обязательно использовать огромную и супер-умную модель.
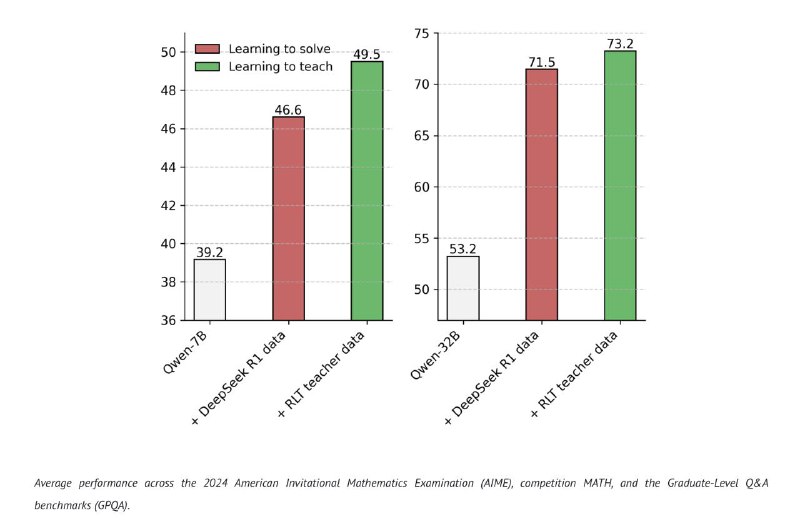
Во-вторых, тесты показывают, что такие учителя учат ризонингу лучше. На примере Qwen 7B и 32B на графике 2 видно, что прирост от RLT выше, чем от обучения с DeepSeek R1.
Пожалуй, самая интересная работа по RL за последнее время. Почитать полностью можно тут. Код и веса обученных моделей, кстати, тоже открыли.
Create: Update:

>>Click here to continue<<
Data Secrets

Share with your best friend
VIEW MORE