OLMo 2 - серия открытых языковых моделей, созданная для развития науки о языковых моделях .
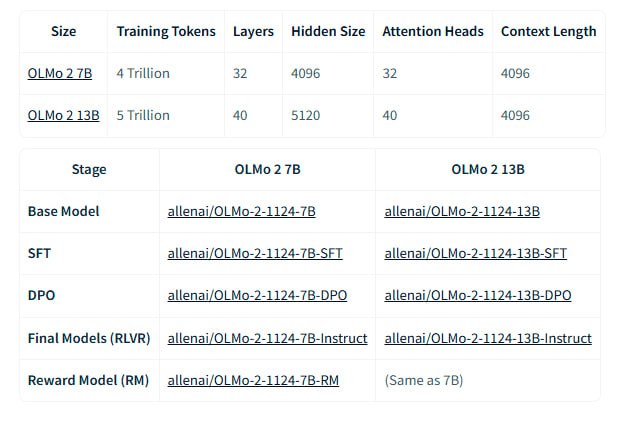
Модели OLMo 2 доступны в вариантах 7B и 13B параметров и обучены на массиве данных объемом 5 трлн. токенов. Они демонстрируют производительность, сопоставимую или превосходящую аналогичные по размеру полностью открытые модели на английских академических тестах.
Разработчики OLMo 2 уделили особое внимание стабильности обучения, используя методы RMSNorm, QK-Norm, Z-loss регуляризация и улучшенная инициализация.
Обучение проводилось в 2 этапа. На первом этапе модели обучались на датасете OLMo-Mix-1124 (3,9 трлн. токенов). На втором этапе использовался специально подобранный набор данных Dolmino-Mix-1124 (843 млрд. токенов), состоящий из веб-данных, материалов из академических источников, форумов вопросов и ответов, инструкций и математических задачников. Для объединения моделей, обученных на разных подмножествах данных, применялся метод "model souping".
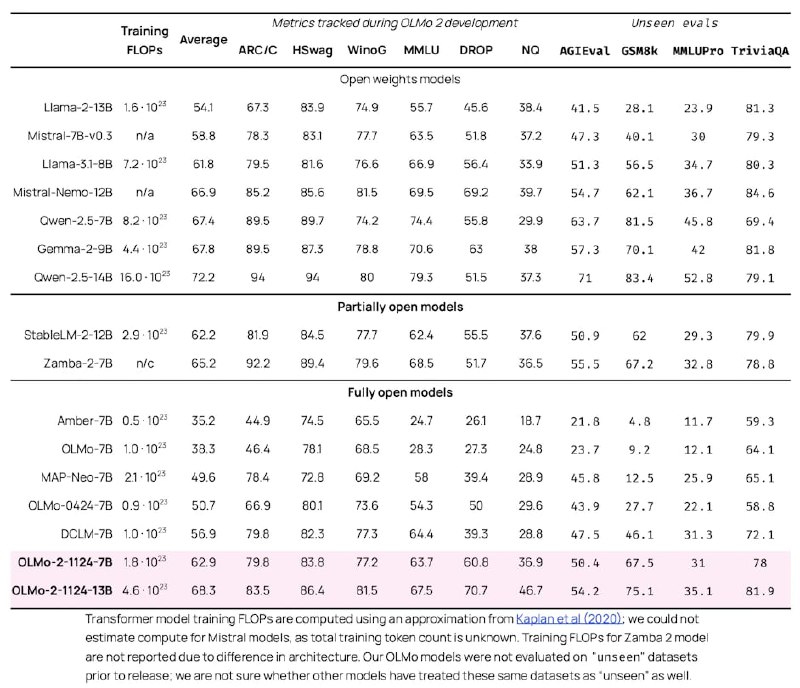
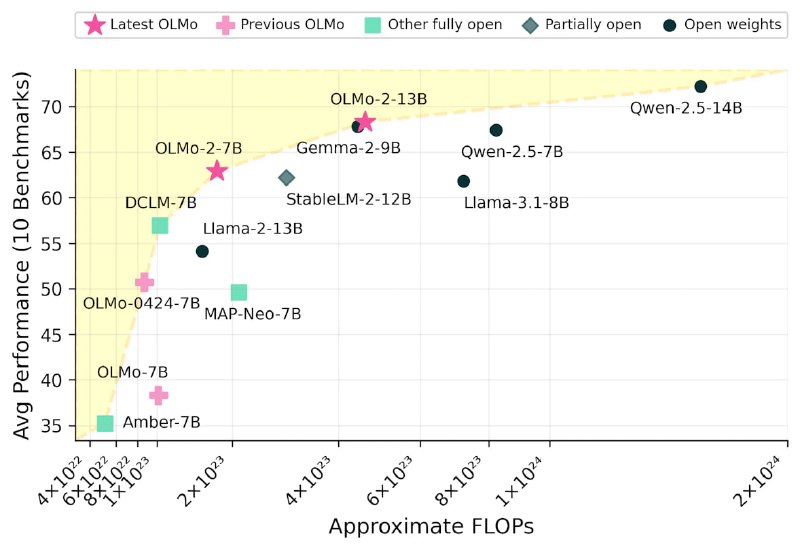
Для оценки OLMo 2 была разработана система OLMES (Open Language Modeling Evaluation System) из 20 тестов для измерения способностей модели. OLMo 2 превзошел предыдущую версию OLMo 0424 по всем задачам и показал высокую эффективность по сравнению с другими открытыми моделями.
from transformers import AutoModelForCausalLM, AutoTokenizer
olmo = AutoModelForCausalLM.from_pretrained("allenai/OLMo-2-1124-7B")
tokenizer = AutoTokenizer.from_pretrained("allenai/OLMo-2-1124-7B")
message = ["Language modeling is "]
inputs = tokenizer(message, return_tensors='pt', return_token_type_ids=False)
# optional verifying cuda
# inputs = {k: v.to('cuda') for k,v in inputs.items()}
# olmo = olmo.to('cuda')
response = olmo.generate(**inputs, max_new_tokens=100, do_sample=True, top_k=50, top_p=0.95)
print(tokenizer.batch_decode(response, skip_special_tokens=True)[0])
@ai_machinelearning_big_data
#AI #ML #LLM #OLMo2