Добиться от LLM нужного поведения - задача нетривиальная, особенно в тонкой настройке с помощью LoRA.
LoRA позволяет адаптировать модель под конкретные задачи, не переобучая ее целиком, но результат сильно зависит от правильно подобранных гиперпараметров. Небольшой, но очень полезный гайд от Unsloth - ваш гид по основным настройкам LoRA, которые помогут повысить точность, стабильность и качество, попутно снижая риск галлюцинаций и переобучения.
Успешное обучение - это, прежде всего, баланс. Слишком высокая скорость обучения может ускорить начальное обучение, но рискует дестабилизировать модель или привести к пропускам оптимальных решений. Слишком низкая замедлит процесс и, как ни странно, тоже помешает обучению или переобучит вашу LoRa. Оптимальный диапазон обычно лежит между 1e-4 и 5e-5.
Аналогично с эпохами: прогонять данные слишком много раз значит рисковать тем, что модель просто "зазубрит" датасет, потеряв способность к обобщению. Недобор эпох грозит недообучением, это когда модель так и не улавливает нужные паттерны.
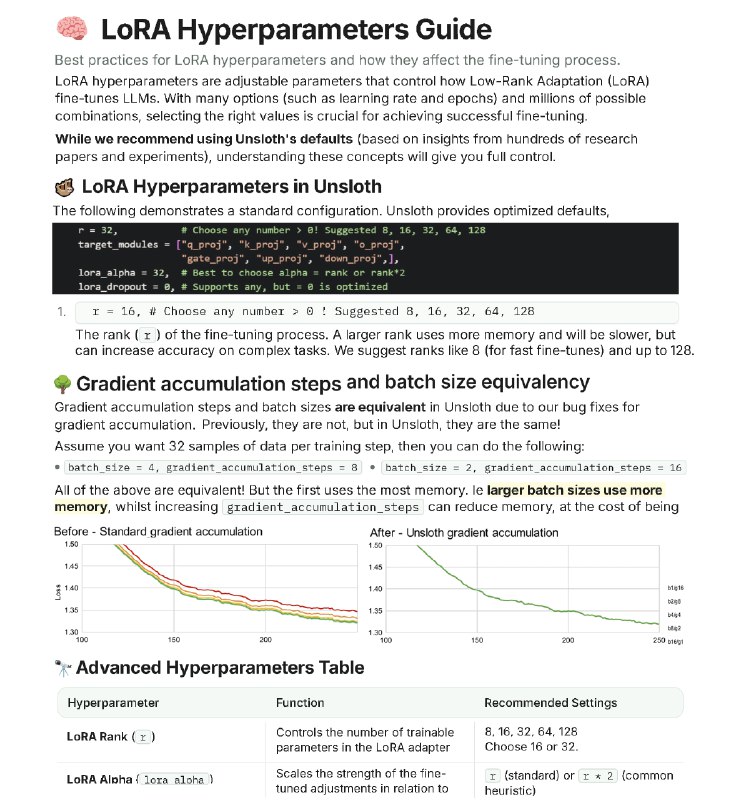
Но вот, вы разобрались с эпохами и скоростью обучения и добрались до специфичных параметров LoRA, например - ранг. Это один из ключевых параметров, он определяет размерность "адаптеров", добавляемых к модели.
Больший ранг дает больше "места" для обучения, но требует больше памяти и времени. Следующий после ранга: lora_alpha. Это своего рода усилитель для этих адаптеров. Часто его ставят равным рангу или удваивают, чтобы усилить влияние дообученных весов.
Unsloth предлагает в своих ноутбуках отличные дефолтные параметры, основанные на большом накопленном опыте файнтюна моделей и предлагает проверенные решения для управления ресурсами и стабильностью.
Подбор гиперпараметров — это всегда итеративный процесс. Экспериментируйте, сверяйтесь с лучшими практиками, и тогда ваши дообученные модели покажут наилучшие результаты.
#AI #ML #LLM #Tutorial #LoRA #Unsloth
Create: Update:

>>Click here to continue<<
Machinelearning
Share with your best friend
VIEW MORE