Reinforcement Learning Teachers (RLT) от Sakana AI - метод обучения LLM рассуждениям, где компактная модель-"учитель" не решает задачи сама, а учится объяснять уже готовые решения так, чтобы студент-модель лучше их усваивала.
Вместо дорогого обучения "с нуля" через проб и ошибку (как в классическом RL), учитель фокусируется на ясности пошаговых пояснений, используя и вопрос, и правильный ответ как подсказку. Это радикально удешевляет процесс и выравнивает цель учителя быть полезным студенту.
Архитектура строится вокруг петли обратной связи. Учителю (например, крошечной модели на 7B параметров) на вход подаются и задача и ее верное решение. Его работа - сгенерировать максимально понятное пошаговое объяснение, как прийти от условия к ответу.
Эффективность учителя измеряется не тем, решил ли он задачу сам (он даже не обязан это уметь), а тем, насколько хорошо студент-модель понимает его объяснение. Ключевая метрика - "логарифмические вероятности": чем выше вероятность, что студент, прочитав объяснение учителя, правильно предскажет следующий шаг или итоговый ответ, тем лучше работа учителя. Это и есть сигнал подкрепления для обучения RLT.
Вся магия метода состоит в этом смещении фокуса RL. Вместо чтоб награждать модель за самостоятельное нахождение ответа (что требует огромных вычислительных ресурсов и приводит к "узкой" специализации), RLT поощряют за педагогическую эффективность.
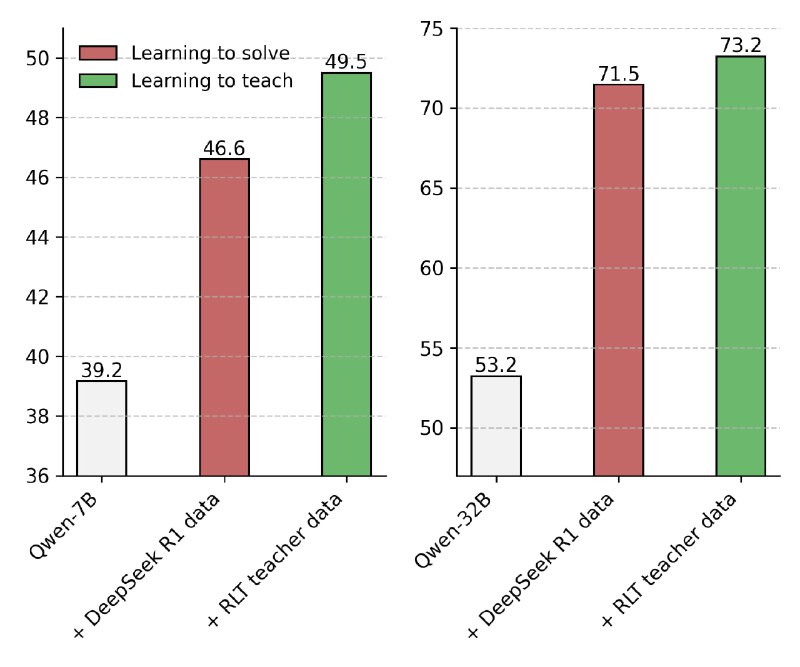
Благодаря наличию готового ответа во время обучения, в роли учителя могут выступать даже небольшие, дешевые модели, которые не смогли бы решить сложные задачи в одиночку. Объяснения от RLT затем используются как высококачественные данные для обучения (дистилляции или "холодного старта") студент-моделей любого размера.
Главный нюанс: метод требует наличия готовых правильных решений для задач в обучающем наборе. Он не заменяет полностью сбор данных, а перепрофилирует их для обучения "преподаванию".
Пока метод тестировался в основном на задачах математики и естественных наук. Но его сила в эффективности: 7B RLT-учитель превосходит в обучении студентов-гигантов ( 671B DeepSeek R1). Он обучает даже студентов крупнее себя (32B) быстрее (менее суток против месяцев) и лучше, а его объяснения четче, без лишнего "шума" вроде юмора или подсказок калькулятора, свойственных традиционным RL-моделям.
@ai_machinelearning_big_data
#AI #ML #LLM #RL #RLT #SakanaAI
Create: Update:

>>Click here to continue<<
Machinelearning



Share with your best friend
VIEW MORE