Create: Update:
GUI-Actor — методика на базе VLM, которая вместо традиционной генерации координат текстом при визуальной обработке интерфейса использует внимание внутри модели.
Чтобы уйти от координатного подхода, в GUI-Actor используется специальный токен <ACTOR>, который "учится" связываться с визуальными патчами, соответствующими целевой области экрана. За один проход модель может запомнить сразу несколько кандидатов на действие.
Например, все кнопки "Сохранить" в сложном интерфейсе. Это очень похоже на человеческое восприятие: видеть сам элемент, а не его позиции по осям Х и Y.
Выбрать наиболее подходящий вариант из элементов-кандидатов помогает "верификатор". Это отдельная модель, оценивающая кандидатов от
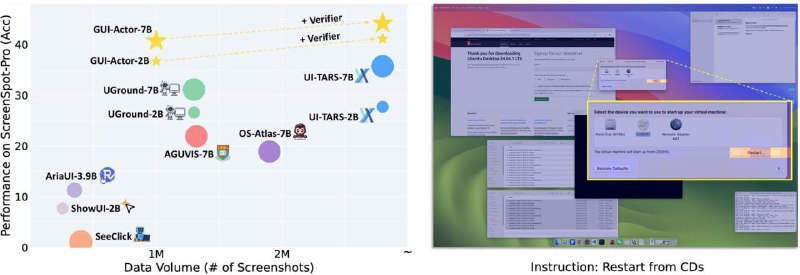
<ACTOR> и отбирающая самый подходящий для действия. Она не только улучшает точность, но и универсальна: ее можно подключить к другим моделям.Обучение требует минимум ресурсов. Можно заморозить основную VLM (Qwen2-VL-7B) и дообучить только новый action head и токены. Это всего ~100М параметров для 7B-модели.
Комбинация из такого быстрого обучения + верификатор почти догоняет полноценно обученные аналоги, сохраняя общие способности базовой модели. Никакого "катастрофического забывания" - агент учится кликать интерфейсы, не разучиваясь описывать картинки.
Результаты тестов на сложном бенчмарке ScreenSpot-Pro с высоким разрешением и незнакомыми интерфейсами (CAD, научный софт) GUI-Actor-7B с Qwen2-VL показал 40.7 балла, а с Qwen2.5-VL — 44.6, обойдя даже UI-TARS-72B (38.1).
На других тестах (ScreenSpot, ScreenSpot-v2) он тоже лидирует, особенно в иконках и текстовых элементах, демонстрируя крутую адаптацию к разным разрешениям и версткам.
В планах - выпуск еще двух моделей на основе Qwen2.5-VL (3B и 7B), демо GUI-Actor, код для модели-верификатора и датасеты для обучения.
@ai_machinelearning_big_data
#AI #ML #VLM #GUIActor #Microsoft