Google Research опубликовал интересную статью «It’s All Connected», в которой предлагают решение проблемы квадратичной сложности трансформеров в обработке последовательностей : фреймворк Miras, который объединяет онлайн-оптимизацию, управление памятью и внимание в единую систему, что в итоге позволяет создавать более эффективные модели.
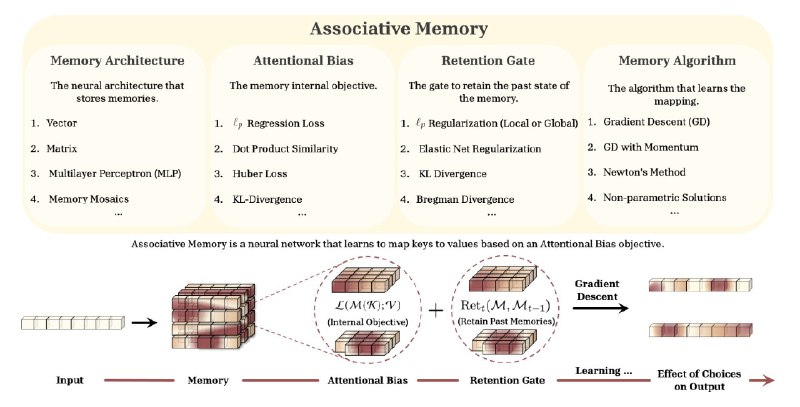
Miras — это 4 компонента: архитектура памяти, целевая функция (смещение внимания), регуляризация удержания и алгоритм обучения. Miras позволяет экспериментировать с loss-функциями (Huber loss для устойчивости к выбросам) и регуляризацией (KL-дивергенция, Elastic Net).
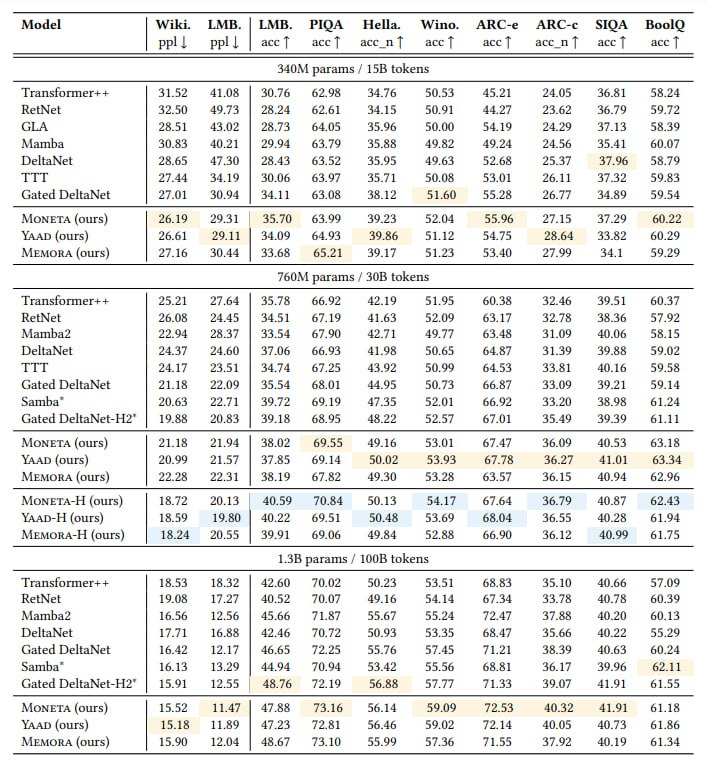
С помощью Miras были созданы 3 тестовые модели — Moneta, Yaad и Memora. Moneta использует Lp-нормы для баланса между запоминанием и устойчивостью, Yaad комбинирует L1 и L2 через Huber loss, а Memora применяет Softmax с KL-регуляризацией.
В экспериментах тестовые модели обошли трансформеры и современные RNN на задачах языкового моделирования и поиска информации в длинных контекстах. На тесте «иголка в стоге сена» (8K токенов) Moneta достигла точности 98.8%, тогда как Mamba2 — лишь 31%.
Статья не просто теоретическое изыскание — это практическое руководство для разработки моделей. Четкая структура Miras помогает систематизировать существующие подходы и экспериментировать с компонентами. Например, замена регуляризации на Elastic Net или Bregman divergence может улучшить управление памятью в нишевых задачах.
Miras — шаг к более осмысленному проектированию архитектур. Если трансформеры — это «кувалда» для масштаба, то описанный в статье подход Google Research - хирургический инструмент, где каждый компонент настраивается под конкретную задачу.
@ai_machinelearning_big_data
Create: Update:

{kind=link}
>>Click here to continue<<
Machinelearning

Share with your best friend
VIEW MORE